-

-
빅 데이터가 만드는 세상 - 데이터는 알고 있다
빅토르 마이어 쇤버거 & 케네스 쿠키어 지음, 이지연 옮김 / 21세기북스 / 2013년 5월
평점 :

품절

1. 어떤 책은 디지털 환경의 복잡하고, 무한한 정보의 흐름에 취해서 정작 기억해야 할 것을 잊어버리는 상태를 걱정한다. 그래서 디지털 치매라는 용어를 만들어서 디지털 환경과의 거리를 유지하라고 권고한다. 한편, 어떤 책은 당신에게 다가오는 엄청난 데이터를 낭비하지 말고, 그것을 경제적으로 이용하라고 권유한다. 우리는 이러한 양측의 주장 사이에서 선택의 기로에 놓여있다.
<빅 데이터가 만드는 세상>은 후자에 관한 주장을 받아들이는 책이다. 이 책은 데이터, 데이터 분석 기술, 데이터 활용에 대한 아이디어. 이렇게 세 가지 요소를 통해서 빅 데이터 세상이 제공하는 정보를 받아들이라고 주장한다.
데이터를 활용하여 창출해낸 결과는 인과성보다는 상관성. 즉, 데이터 분석 결과를 바탕으로 알고자 하는 것에 대한 원인보다는 결과에 중점을 둔 것이지만, 그 정도만 예측할 수 있더라도 많은 부분에서 심각한 문제 발생을 막을 수 있으므로 사회적으로 비용 절감 효과를. 그리고 데이터를 분석해서 소비자의 성향을 예측할 수 있으므로 마케팅 효과의 측면에서 이익을 창출할 수 있다고 말한다.
2. 빅 데이터를 만드는 데이터, 분석 기술, 아이디어. 세 가지 조건 중에서 가장 중요한 것은 데이터라고 말한다. "IT 기술에서 중요한 것은 더 이상 'T'가 아니다. 'I'다. 왜냐하면, 데이터는 가공되지 않는 금광과 같기 때문이다." 라고 작가는 비유한다. 데이터의 보유와 다양성을 통해서. 분석가와 기획자들은 데이터를 수집할 당시 예측하지 못했던 2차적 문제에 관해서 예측할 수 있는 도구를 생성할 수 있고, 많은 데이터를 통해 예상 확률을 더욱 높일 수 있다고 말한다.
3. 빅 데이터로 모든 확률을 계산하고 해석하는 세상에 부작용은 존재한다. 그것은 인터넷에서 우리가 남기는 데이터 잔해를 통해서 자신도 모르게 나의 정보가 외부로 누출될 수 있고, 그러한 데이터 잔해의 분석 결과. 우리가 저지르지도 않은 미래의 범죄 가능성을 예상하여 우리들을 잠재적인 범죄자로 만들어버릴 수도 있다.
또한, 데이터를 맹신하는 사회적 환경과 자신의 성과라는 압력에 굴복하여 데이터를 조작하여 각종 비리를 저지를 가능성도 있다고 한다. 이러한 데이터 세상의 부작용에 대해서 우리가 할 수 있는 일이란 인간적인 정의감에 호소하는 일밖에 없고, 데이터를 사용하는 사람들의 도덕성에 호소하는 길밖에 없는 듯하니 통제와 규제라는 측면에서 좀 더 연구가 필요한 듯도 싶다.
4. 나는 데이터 수집 필요성과 그것을 책과 연관 지어서 생각해본 적이 있다. 우리가 읽고 기억하는 것에는 한계가 있기 때문에 유용한 구절들을 데이터 저장과 검색이 동시에 가능한 공간에 입력해두고, 필요할 때 검색 도구를 통해 추출하는 방식이 필요하다고 생각했었고, 나는 그것을 블로그를 통해서 할 수 있다고 봤다. 이미, 많은 작가들이 자신의 집필을 위해서 개인 공간에 유용한 데이터를 수집하고 있다고 한다.
집필을 위해서가 아니라 책을 잘 읽고, 이해하기 위해서도 자신이 만족할 만한 수준으로 데이터를 저장할 필요가 있다. 책을 읽으면서도 사유를 일으킬 수 있는 데이터에 갈증을 자주 경험했었다. 문제는 그것을 수집하기 위해 걸리는 시간인데. 단순한 수작업을 통해서는 엄청난 제약이 있기 때문에 스캐너 같은 기구를 통해서 지금의 PDF나 전자책의 형식처럼 스마트폰에 이미지로 디지털화하는 방식과는 다르게 한 글자씩 데이터로 처리할 수 있는 방식을 고민해 봤었다.
5. 그것을 거의 완벽하게 이뤄낸 사례가 있다. 엘리엇 부가 쓴 <자살을 할까 커피 한잔 할까>라는 책이다. 이 책은 아주 유명한 작가들의 잠언을 수집해서 그것을 데이터로 만들었고, 하나의 키워드를 검색해서 나온 결과를 이어 붙여서 어디에서도 보지 못했던 새로운 하나의 짧은 글을 창조해내는 작업을 수행했다.
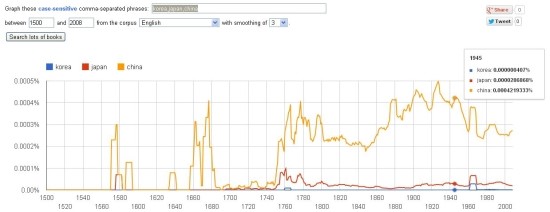
6. 역시. 시간이 오래 걸리더라도 이 블로그를 지금보다 더 많은 데이터를 가진 공간으로 만들어놔야겠다. 그런 생각을 해본다. 스캐너를 통해서 PDF 파일을 만들고, 그것을 키워드를 통해서 검색이 가능하게 만드는 방법에 대해서 더 생각해봐야겠다. 지금도 이러한 기능이 가능한지도 궁금하다. 네이버 책의 본문 검색 기능 같은 것을 원한다. 구글은 몇 천만권의 책을 스캔해서 키워드를 검색하면 그 키워드가 과거와 현재 얼마나 많이 쓰이고 있는지를 알 수 있었다.
예를 들어, south korea와 north korea나 korea, japan, china의 사용 빈도를 조사해볼 수 있다. 이 도구를 사용해서 남성과 여성의 입력 빈도를 분석하고 여성의 검색 증가 추세를 발견하고, 그것을 여성의 신분 상승이라는 결론으로 매듭짓는 경우도 있었다.