코어 아키텍쳐의 매크로퓨전이 EM64T를 지원하지 않는다는 내용은 인텔의 내부 문서를 통해서 알려졌다.
이 문서의 출처는 프리젠테이션 내용으로 보아 인텔 개발자 포럼(Intel Developer Forum)에서 나온 것으로 보이며, 명령어 큐(Instruction Queue)의 최적화라는 부분에서 언급이 되었다.

IDF 중 언급된 EM64T long mode 시 매크로퓨전 미지원 내용
매크로퓨전에 대해서는 이미 [정보] ‘코어 아키텍쳐’ 그 핵심을 들여다본다 에서 다룬 적이 있다. 본 내용에 앞서 코어 아키텍쳐에 관한 내용 중 4번 디코딩 유닛 : 변화의 바람과 5번 똑똑해진 디코딩 : 매크로/마이크로 퓨전 편을 보면 많은 도움이 될 것이다.
다음의 그림은 코어 마이크로아키텍쳐의 블럭 다이아그램이다. 이 부분에서 필자가 다루고자 하는 부분은 명령어 페치(Instruction Fetch)부터 디코드(Decode) 부분까지이다.
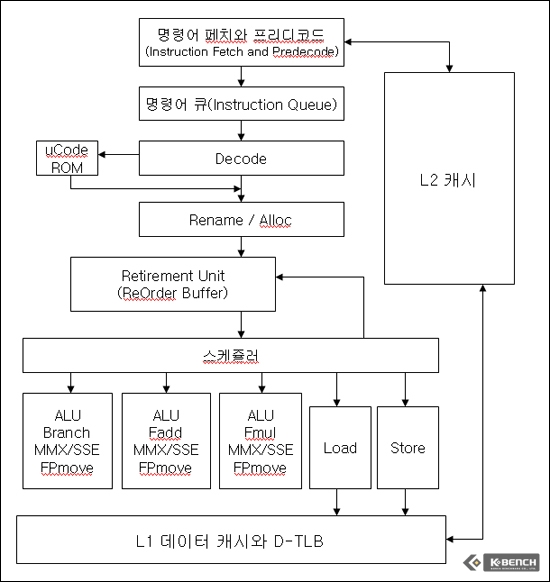
코어 마이크로아키텍쳐 블록 다이아그램
위의 프리젠테이션 자료를 보면 매크로퓨전은 EM64T long mode에서 지원을 하지 않는다고 되어 있다. 매크로퓨전이 EM64T long mode에서 지원을 하든지 말든지 상관은 없지만 지원을 하지 않을 경우 어느 정도의 성능 하락이 발생하는지를 알아봐야 한다. 다시 말하자면 매크로퓨전이 이루어질 경우 성능 향상 폭은 얼마인가?가 주된 내용이 될 것이다.
매크로퓨전은 코어 마이크로아키텍쳐의 실행 단계 중 명령어 큐(Instruction Queue) 부분에서 일어난다. 매크로퓨전을 간단히 정의하자면 관련이 되는 연속되는 명령어 2개를 하나로 묶어서 1개의 명령어처럼 디코드한다는 뜻이다.
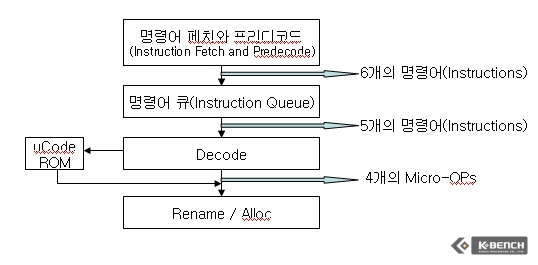
그럼 여기에서 매크로퓨전의 효용성에 대해서 생각을 해봐야한다. 매크로퓨전으로 인해서 성능 향상이 수십 %까지 발생한다면 EM64T에서 매크로퓨전을 사용하지 못하는 것은 크나큰 손실이고 그렇지 않다면 크게 고민을 하지 않아도 되기 때문이다.
모든 일에는 순서가 있는 법이며 CPU 내부에서 처리 과정 역시 순서라는 것이 있다. 그 순서에 따라서 이제 CPU 내부에서 처리되는 것들을 살펴보도록 하자.
우선 첫 번째로 하는 일은 32KB의 L1 명령어 캐시로부터 캐시된 명령을 가져와야 한다. 이때에 명령어 페치 유닛(Instruction Fetch Unit)이 16바이트 단위로 계속 불러와서 프리디코드(PreDecode)로 넘겨준다. 페치 유닛은 명령어가 포함된 데이터 블럭을 계속 불러다가 프리디코드로 보내주는 역할을 하는 것이다.
그런데 이 16바이트짜리 블럭에는 명령어가 담겨 있긴 하지만 몇 개가 담겨 있는지는 아무도 모른다. 다만 명령어가 들어있는 캐시에서 가져온 것이니 당연히 명령어가 포함되어 있을 거라는 단순한 계산만으로 명령어 페치는 가져오는 것이다.

프리디코드가 할 일은 이 블럭에서 명령어들을 골라 내는 일이 첫 번째 주요 임무이다. 프리디코드는 한 번의 사이클에 6개의 명령어를 처리할 수 있다. 여기에서 처리한다는 뜻은 16바이트짜리 블럭에서 6개의 명령어 부분을 찾아내서 마킹(marking)을 한다는 뜻이다. 만약 6개보다 작으면 작은 대로 보내지만 효율이 떨어지게 될 것이다. 반면 7개 이상이 된다면 두 번의 사이클로 나눠서 6개를 먼저 한 사이클로 보내고 다음 한 사이클에서는 남은 한 개를 보낸다. 역시 낭비가 되는 것이다.
여하튼 그것까지 프리디코드가 걱정할 필요는 없다. 명령어 큐가 알아서 해주기 때문이다. 명령어 큐에서는 프리디코더가 보내온 명령어들을 차곡차곡 저장을 해둔다. 물론 무한대로 저장이 가능한 것은 아니고 18단계 깊이로 되어 있기 때문에 저장 공간에 별다른 문제는 없다. 다만 이 큐에 충분한 명령어들이 없다면 문제이다.
순차적으로 쌓여 있는 명령어들을 이제 명령어 큐에서 다시 5개씩 디코드로 보낸다. 이때 디코드로 보내는 5개의 명령어는 5개일 수도 있지만 6개일 수도 있다. 연속되는 명령어 중 매크로퓨전이 가능한 명령어가 연속되어 있다면 이를 하나로 묶어 줄 수 있기 때문이다.
매크로퓨전은 이렇게 이루어진다. 그렇다면 어느 정도의 효율이 있을까. 간단하게 말해서 한 번에 5개 처리 할 수 있는데 여기에 덤으로 하나 더 넣어서 6개가 된다면 20% 빨라진다. 매크로퓨전만으로 20%나 향상이 되는 것이다. 하지만 역시나 이론은 이론일 뿐 실제 매크로퓨전이 되는 과정에서 손실이 발생하게 될 것이며, 몇 번의 사이클을 거쳐도 매크로퓨전이 발생하지 않는 경우도 있을 것이다. 만약 3번의 사이클에서 매크로퓨전이 1번 발생한다면 평균적으로 7%도 안 되는 성능향상만이 있게 된다. 7%도 높게 잡은 것이며 실제로는 3~4% 정도나 될 것이라고 전문가들은 말하고 있다.
3~4%정도의 효율이라면 매크로퓨전을 지원하지 않는다고 해서 크게 문제가 될 것은 없다. 코어2듀오의 기본 성능이 어찌나 좋은 표시도 나지 않을 것이기 때문이다.
그러나 문제는 여기에서 그치지 않는다.

명령어 페치와 프리디코더 최적화 방법에 관한 P.T.
EM64T 기능이 있는 모든 인텔 프로세서에는 확장 범용 레지스터 8개와 SSE 레지스터 8개가 추가되어 있다. 이 레지스터들을 활용하기 위해서는 REX라는 특정 프리픽스(prefix-접두어)를 붙여야 한다. REX 접두어를 붙이게 된다면 명령어 길이가 더 길어지게 되는 것은 당연한 것이다. 명령어의 길이가 길어진다라는 말은 프리디코더에서 한 번의 사이클에 처리할 수 있는 명령어의 수가 감소한다는 뜻이다. 16바이트로 한정된 블럭에서 확장 레지스터 부분을 사용한다는 뜻의 1바이트짜리 REX를 붙이게 되면 6개짜리 명령어 블럭도 4개나 3개로 줄어들 수 밖에 없다.
그렇게 되면 당연히 효율이 떨어지게 된다. 그렇다고 이를 사용하지 말라는 말은 64bit의 장점 중 일부를 포기해야 한다. 프로그래머 입장에서는 이러지도 저러지도 못하는 상황에 부딪히게 된 것이다. 이 문제는 앞서 매크로퓨전을 지원하지 않는 것보다 꽤 심각하다. 64bit 확장레지스터를 사용하지 않거나 REX 프리픽스의 사용을 자제한다면 그래도 효율은 있겠지만 확장 레지스터에 명령어를 저장해 두고 사용하면 캐시 액세스를 자주할 필요가 없기 때문이다.
하지만 위의 두번째 문제는 비단 EM64T에서만 발생하는 것은 아니다. AMD64 역시 64bit에서는 확장 레지스터를 사용하고 이와 같은 프리픽스가 붙기 때문이다. 그렇기 때문에 두 번째 문제점은 인텔과 AMD 모두에게 해당이 되는 문제이다.