펜티엄 프로 이후로 인텔은 명령어를 가져오고 실행하는데 있어 비순차적(Out Of Order) 실행을 도입했다. 메모리 재정렬 버퍼-MROB(Memory Reorder Buffer)에서도 비순차적 실행을 위한 명령어/데이터 재정렬시에 인텔은 이 부분에서도 캐쉬 메모리, 혹은 메인 메모리에서 찾는 데이터를 가져오는데 필요한 레이턴시를 줄일 수 있는 방법을 찾아냈는데 이것을 메모리 디스앰비규에이션(Memory Disambiguation) 이라 지칭하고 있다.
일반적으로 메모리 그리고 캐쉬에서 데이터를 가져오고 저장하는 메모리 연산 유닛 기능은 가장 간단하게 Load(불러오기)와 Store(저장하기)로 정의된다. 비순차적 실행을 위한 재정렬에 있어 프로세서 입장에서 이 Load와 Store의 순서를 정하는 것은 매우 중요하다. 만약 한 데이터를 특정 저장소(캐쉬, 메모리 혹은 레지스터 파일)에서 저장(Store)해서 다시 불러오기(Load)를 시행하는 연산 과정이 있다고 가정하면, 이 시행 순서를 바꿀수가 없다. 만약 먼저 Load를 같은 장소에서 불러오고 다서 Store를 한다면 결국 데이터는 원하는 값대로 갱신되는 것이 아니기 때문이다. 데이터 저장소 입장에서 남아 있는 데이터 값의 입장에서 보면 이해하기 쉽다. 즉 Load를 시행하기 위해서는 Store가 진행되는 동안 기다려야 한다.
위와 같은 이유로 인해서 비록 비순차적 실행을 도입했더라도 인텔은 넷버스트 아키텍쳐의 펜티엄4까지 반드시 Store와 Load에서 같은 메모리 주소를 참조하고 있는지 반드시 확인하도록 했다. 만약 섞인 메모리 명령어 중에서 Store가 저장 메모리 장소가 정확하지 않을 경우 이를 Load 이전에 실행하는 것을 엄격하게 막았다. 즉 만약 Store의 주소가 명확해지고 나서 Load와 같은 메모리 장소를 사용한다는 것이 알려지게 되면 결국 잘못된 연산 결과를 낼 수 있었기 때문이다.
문제는 이와 같은 Load, Store간의 관계에서 실질적으로 같은 메모리 장소를 사용하고 반드시 순차적으로 실행되어야 하는 것 (이것을 Memory Alias라고 인텔은 부른다)이 실질적으로 ROB에서 시행되는 전체 명령어 중에서 단 3% 정도 밖에 되지 않았다는 것. 나머지 97%는 같은 주소를 참조하지 않는 False Aliasing이었다고.
이 경우에는 Load, Store의 순서를 변경할 수 있다. 위에서 언급했듯이 메모리 디스앰비규에이션은 데이터를 불러오고 저장하는데 있어 레이턴시를 줄이는 것이 목표라고 했다. 그렇다면 이 순서를 바꾸는 것으로 어떻게 레이턴시를 줄일 수 있을까? 아래 그림을 참조하도록 하자.
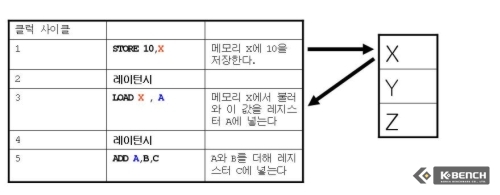
먼저 STORE와 LOAD가 같은 메모리 값을 참조하는 경우를 보자. 이 경우 X에 먼저 10이란 값을 저장한다. 그렇다면 다음 LOAD는 같은 메모리 장소X에 저장된값을 불러와서 레지스터 A에 저장해야 하기 때문에 STORE가 실행되는 1클럭 동안 전까지 기다려야 한다. 이는 STORE가 완료되고 LOAD를 시행하기 이전에 1 클럭의 레이턴시가 발생한다는 것을 의미한다. 이후에 A, B 레지스터에 적힌 값을 더해서 레지스터 Y에 저장하게 되는 과정에서도 역시 X에서 값을 불러와서 A에 넣기 위해서 1클럭을 소요하고 이는 이만큼 기다려야 한다는 것을 의미한다. 이 경우에는 STORE, LOAD의 순서를 바꿀수 없으며 이것이 바로 위에서 언급한 Memory Alias이다.
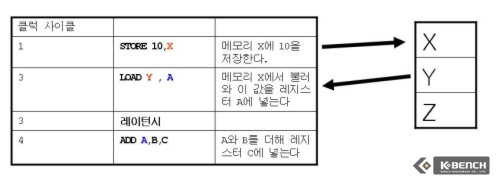
그러나 만약 STORE와 LOAD가 같은 메모리 값을 참조하지 않는다면 어떻게 될까?(이 경우를 False Aliasing이라고 한다) 그림에서 2번째 경우를 보면 STORE의 경우 메모리 X를 참조하고 LOAD의 경우 메모리 Y를 참조한다. 이 경우 LOAD가 STORE가 완료될때까지 기다릴 필요가 없기 때문에 레이턴시가 발생하지 않는다. 그러나 여전히 ADD에서 필요한 값을 구하기 위해서는 LOAD가 완료될 때까지 기다려야 한다. 이것이 현제 넷버스트까지 할 수 있던 최선의 방법이었다.
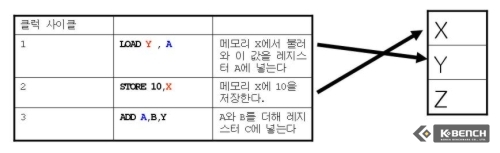
그러나 만약 같은 메모리를 참조하지 않는다면 이 과정에서는 아예 레이턴시를 없애 버릴 수도 있는데 이는 실행 순서를 바꿈으로써 가능하게 된다. 메모리 디스앰비규에이션이 적용될 경우 STORE와 같은 메모리 참조값을 사용하지 않는 LOAD를 STORE보다 실행한다. 이로 인해서 뒤에 ADD 연산은 물론 LOAD가 완료될때까지 기다려야 하지만 이 기다리는 시간을 허비 하지 않고 바로 STORE 작업을 시행할 수 있으며 낭비되는 레이턴시를 없앨 수 있다.
인텔은 메모리 디스앰비규에이션, 즉 LOAD와 STORE의 순서를 바꾸어 레이턴시를 낮추는 것만으로도 최고 40%의 성능향상이 있다고 밝혔다.