매크로 Op 퓨전(Macro Ops Fusion)
그렇다고 해서 코어의 디코더 부분이 P6에서 단순히 디코더 수를 늘린 것은 아니다.
코어 아키텍쳐는 각 명령어가 Micro-Op으로 디코딩 되기 전에 몇몇 특정 종류의 명령어를 묶어서 하나의 Micro-Op으로 만드는 기능을 구비하고 있다. 매크로 퓨전(Macro Fusion)이라는 이름의 이 기능은 비교 명령인 cmp(Compare)와 조건 분기 명령인 Jne(Jump if Not Equal)을 하나의 Micro-Op으로 만들어 연산 유닛에 보낸다. 즉 매크로 퓨전 없이는 각기 명령어마다 1개의 디코딩 과정을 거지고 또 각기 연산 유닛에 보내졌던 것을 하나의 Micro-Op, 위의 예에서는 cmpjne,으로 만들어 연산 유닛에 보내게 됨으로써 디코딩 유닛에서 전체적으로 디코딩 해야 할 명령어 수가 줄어들고, 결과적으로는 더 많은 명령어를 (같은 사이클 내에) 디코딩할 수 있다는 것을 의미한다. 즉 코어가 가진 4개의 디코더(1개 콤플렉스, 3개 심플)에서 한 사이클에 4개의 명령어 디코딩이 가능한 것을 매크로 퓨전으로 최대 5개까지 한 사이클에 할 수 있다는 것이다.
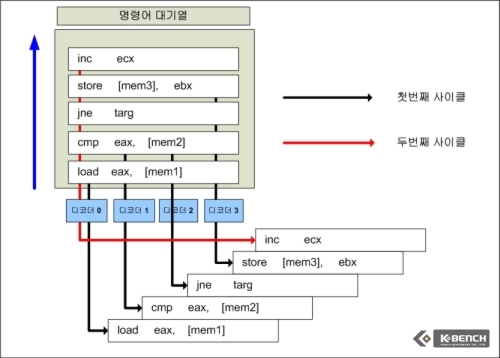
이 예제는 일반적인 x96 명령어가 디코딩 되는 과정을 그린 것이다.
만약 디코더 유닛이 4개가 붙어 있다면 아래서부터 차례로 대기열에 대기중인 명령어들이 4개가 디코딩 되고 5번째 명령어는 다시 “디코더 0”에서 2번째 사이클에서 디코딩 된다.
그러나 매크로 퓨전이 적용된 코어 아키텍쳐는 cmp와 jne를 하나의 Micro Op으로 디코딩 가능, 결국 해당 예제에서 1사이클만에 명령어 5개를 디코딩할 수 있다는 것을 보여주는 것이다.
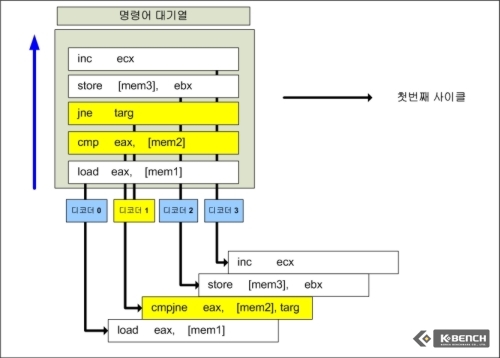
인텔에서는 x86 명령어(Instruction)-즉 디코더에서 이보다 작은 단위의 연산인 Micro Op으로 쪼개기 전까지 명칭-를 Macro Op이라고 부르는 것으로 보인다. 실질적으로 매크로 퓨전이 궁극적으로 의미하는 바는 각기 다른 Micro Op으로 쪼개질 명령어(Instruction, 즉 Macro-Op)을 하나의 Micro Op으로 디코딩을 할 수 있다는 의미이다.
그렇다면 실질적으로 컴퓨터를 사용시에 프로세서에서 이 매크로 퓨전으로 실질적인 성능 향상은 어느 정도 될까? 이는 전적으로 혼합, 즉 퓨전의 대상이 되는 cmp, jne의 사용빈도에 달려 있는데 애플리케이션 구동시 전체 총 디코딩되는 Micro-Op의 전체 수를 약 15%선까지 줄일 수 있다고 한다.
이는 단순히 디코딩 되는 명령을 줄여 성능을 끌어올리는 이점만을 제공하는 것은 아니다. 디코더가 처리해야할 명령의 수가 준다는 것은 바로 전력 소모량을 낮출 수 있다는 결과 역시 가져온다.
마이크로 Op(Micro-Op) 퓨젼
위의 매크로 퓨전이 명령어의 2개의 명령어를(코어 아키텍쳐의 경우 Cmp와 Jne가 되겠다) 하나의 Micro-Op으로 디코딩할 수 있는 명령어(cmpjne)로 만드는 과정을 거치는 것이라면 마이크로 퓨전은 이미 인텔이 요나에서 선보였던 것으로 이미 명령어(Instruction)에서 디코더를 지나 Micro Op으로 쪼개진 상태에서 하나로 묶을 수 있는 Micro Op들의 쌍을 찾아서 묶어서 연산 유닛으로 보낸다는 것을 의미한다. 이 기술도 근본적으로 처리할 Micro-Op의 수를 줄여줌으로써 성능 향상과 동시에 전력 소모량 절감의 효과를 가져온다. 인텔은 마이크로 퓨전으로 전체 파이프라인에서 처리해야할 Micro Op의 수를 약 10% 정도 절감할 수 있다고 밝힌 바 있다.
한편 이러한 Micro-Op 절약하기 테크닉만이 코어 아키텍쳐의 디코딩 유닛에서 유일한 장점은 아니다. 넷버스트 아키텍쳐의 경우 1개의 대형 디코딩 유닛을 갖추고 있지만 (이 자체가 하나의 거대한 콤플렉스 디코더로 봐야 한다) 사이클당 3개의 Micro Op 만을 트레이스캐쉬를 거친 히후에 연산 유닛으로 보낼 수 있다. 그러나 코어의 경우 총 4개( 3개 심플 + 1개 콤플렉스)로 사이클당 7개의 Micro Op을 연산유닛으로 보낼 수 있다