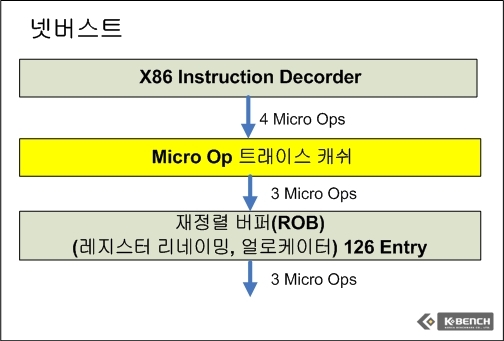
넷버스트가 이전 P6 아키텍쳐에서 가장 많은 차이점으로 부각했던 것은 바로 매우 많은 단계의 파이프라인, 즉 클럭 속도를 끌어올릴 수 있다는 것이었다. 그러나 시스템 전체 측면에서 프로세서 클럭을 높에 끌어올릴 수 있다는 것이 전체적인 성능향상을 의미하지는 않는다. 현재 펜티엄 프로세서의 최고 클럭은 3.8GHz이며 반면 메인 메모리의 클럭 속도는 667MHz에 지나지 않는다. 더 정확히 하자면 내부 데이터 버스의 폭과 어드레싱 능력, 그리고 대역폭을 비교해야 겠지만, 일단 프로세서 클럭을 끌어올리는 것, 그리고 깊은 단계의 파이프라인은 결국 이를 받쳐주는 메모리 기술과 데이터 수집/캐쉬/재정렬 기술이 없으면 실질적인 성향 향상을 도모하기는 어렵다.
때문에 인텔은 넷버스트의 주요 기능으로 트레이스 캐쉬(Trace Cache)를 도입했다. 트레이스 캐쉬는 Micro-Op (프로세서 연산 유닛에서 처리하기 위해 명령(Instruction)을 단순 연산자, 일례로 덧셈이나 곱셈으로 쪼갠(Decoding) 것을 의미하며 이러한 x86의 특징으로 인해서 RISC와 CISC의 경계가 모호해졌다고 해도 무방하다)을 캐쉬에 담아놓고 프로세서 연산 유닛이 이를 필요로 할 경우 명령어를 불러서 다시 디코더를 통해서 나온것을 기다리지않고 바로 디코딩된 Micro-Op을 가져올 수 있도록 저장해놓은 캐쉬 공간이다.
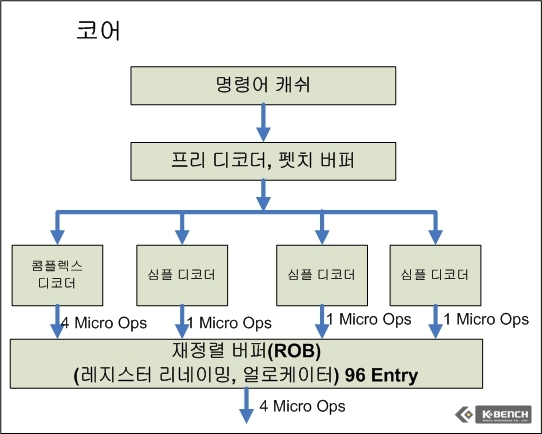
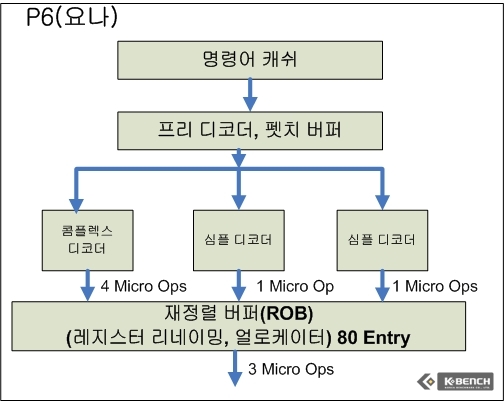
트래이스 캐쉬의 도입으로 인해서 인텔은 트레이스 캐쉬 이전 단계에 거대한 디코더 유닛을 넷버스트에서 필요로 했다. 그리나 이전 요나의 경우 디코더를 심플 디코더 2개, 콤플렉스 디코더 1개 (심플 디코더의 경우 1개의 Micro Op으로 변환할 수 있는 명령어(Instruction)을 변환하며 콤플렉스의 경우 1개의 명령어가 1-4개의 Micro Op들로 변환되는 명령어에 대한 디코딩을 진행한다)를 갖추고 있으며 트래이스 캐쉬 같은 별도의 보조 캐쉬없이 바로 재정렬 버퍼(Redorder Buffer) 공간을 통해서 연산 유닛으로 데이터가 공급되게 된다.
그러나 코어 아키텍쳐의 경우에는 넷버스트 대비 상대적으로 파이프라인 단계가 14단계로 짧다(아직 각 파이프라인 각각 단계에 대한 자세한 정보는 인텔이 공개하지 않았다). 파이프라인 개수가 줄어든 것도 한 가지 이유이고, 진보된 캐쉬 기술을 도입한 것도 이유이겠지만 일단 넷버스트가 자랑스럽게 내밀었던 하이퍼파이프라인(높은 단계의 파이프라인)과 트레이스 캐쉬는 코어 아키텍쳐에서는 자취를 감추었다. 대신 P6에서 사용했던 디코더 수를 늘렸으며 심플 디코더가 3개, 1개의 컴플렉스 디코더를 갖추고 있다. 이외에 바로 중간 캐쉬(트래이스 캐쉬) 없이 연산 유닛으로 공급되는 구조를 갖춘 것은 P6와 유사하다.