“더 높은 성능을 구현하기 위해서 더 높은 전력을 소모할 필요는 없다“
이는 인텔이 지난 개발자 포럼에서 코어 아키텍쳐를 위와 같은 발언으로 소개했다.
인텔의 새로운 마이크로아키텍쳐에 대한 고민은 특정 부분이 아니라 데스크탑, 모바일, 서버 전 분야에 대한 고민에서 출발한 것이다. 데스크탑 부분에서 인텔은 높은 파이프라인 단계(31 단계)의 넷버스트 아키텍쳐 펜티엄4로 클럭을 끌어올리며 성능을 높이는데 성공했다. 그러나 클럭 속도를 끌어올릴 수록 높은 전력소모량과 발열도 같이 증가, 결국 이러한 방법으로 성능 향상은 한계에 도달했다. 펜티엄4는 0.25>0.18>0.13>0.09 미크론으로 제조 공정의 미세화에도 불구하고 결국 전력 소모량을 낮추지는 못했다. 클럭 경쟁을 종료한 인텔은 결국 멀티 코어와 캐쉬 크기를 끌어올리는 방법을 선택하게 되는데, 여전히 현 넷버스트 아키텍쳐에서는 클럭을 낮추더라도 코어수를 늘리고 캐쉬를 늘리는 만큼 전력 소모량이 그대로 증가했기 때문에 본격적인 멀티 코어 시대에 맞는 아키텍쳐가 절실히 필요하게 된 것이다.
모바일 부분에서는 넷버스트의 이런 구조 때문에 펜티엄4M 이라는 모바일용 데스크탑 프로세서를 내놓고도 또 다른 아키텍쳐의 펜티엄M까지 내놓게 된다. 노트북의 특성상 배터리 수명이 성능 이상으로 중요한 인자이며 휴대성을 강화한 슬림형 노트북의 경우 작은 크기의 냉각 솔루션 역시 필요했기 때문이다. 또한 24시간 무결성 동작이 필요하고 블레이드 서버와 같이 높은 설치 밀도를 요구하게 된 서버 환경에서도 마찬가지이다.
결국 인텔은 데스크탑과 서버 부분에서는 넷버스트 아키텍쳐의 프로세서, 그리고 모바일 프로세서에서는 펜티엄M의 배니어스 코어 아키텍쳐로 2개의 아키텍쳐 라인을 동시에 운용하게 되는데 코어 아키텍쳐의 등장은 그동안 분리되었던 각 분야에서 아키텍쳐를 통합하는 것과 동시에 앞으로 성능향상의 주요 지침이 될 멀티 코어 프로세서 전략에 있어 핵심이 된다.
코어 아키텍쳐는 인텔 이스라엘팀이 개발한 것으로 이 팀은 현재 펜티엄M 프로세서의 아키텍쳐를 개발한 팀으로 알려져 있다. 코어가 발표되면서 가장 논쟁거리가 되었던 것은 과연 이것이 “넷버스트를 포기한 인텔이 펜티엄 3로 회귀”하였냐는 것인데 코어 자체적으로는 P6 아키텍쳐에 기반을 둔 배니어스부터 출발했지만 펜티엄3로 회귀로는 보기 어렵고 그렇다고 펜티엄3에다가 단순히 넷버스트에서 배운 것을 몇 개 적용했다고 보기에도 어렵다. 코어는 위 언급한 아키텍쳐들의 장점을 가지고 왔지만 백지에서 출발해서 설계한 완전히 새로운 차세대 아키텍쳐로 보아야 한다.
물론 뒤의 코어 아키텍쳐에 대한 설명에는 P6 , 그리고 넷버스트와의 비교를 통해서 차이점을 위주로 언급하게 될 것이지만, 이것은 코어가 이 아키텍쳐들에서 시작했다기 보다는, 인텔의 진화 선상에서 이전 세대의 아키텍쳐와의 관계를 설명하기 위한 것으로 보는 것이 옳다.
멀티 코어가 프로세서 업계에서 대세가 되면서 x86 프로세서이외에도 RISC 프로세서, 그리고 여타 아키텍쳐의 프로세서들도 모두 멀티 코어로 진화하고 있다. 그러나 인텔의 멀티 코어 전략은 여타 업체와는 많은 차이점을 보인다.
현재 8개의 코어를 장착한 썬 마이크로시스템즈의 나이아가라(T1)이나 IBM, 소니, 도시바의 합작인 셀 프로세서의 경우 멀티쓰레드, 즉 다수의 쓰레드를 동시에 처리하도록 하는 연산의 병렬화, 즉 코어수를 늘림으로써 병렬연산 기능 강화에 치중한 대신, 싱글 쓰레드 성능은 어느 정도 포기한 구조를 택하고 있다. 이는 멀티 코어 프로세서를 구성하는 각 코어에 수퍼스케일러 프로세서의 대표적인 특징인 비순차적 실행(Out Of Order Execution)을 없앤 특징(즉 반대로 초기 프로세서의 특징인 순차적(In-Order Execution) 실행 구조를 택하고 있다)에서 잘 드러난다. 즉 각 코어구조를 최대한 단순화 시키고 여러 개의 코어 구동을 통해서 연산 병렬화에 주력하겠다는 것.
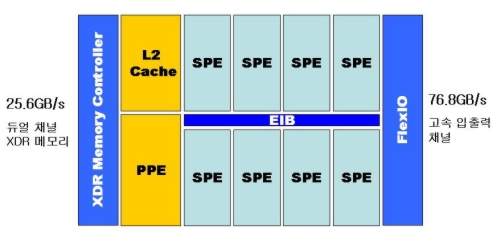
<셀 프로세서의 기본구조. 간단한 구조의 SPE로 구성되어 있다>
인텔의 코어 아키텍쳐는 이 부분에서 여타 업체의 ‘멀티 코어’전략과는 확연히 다른 모습을 보여주며 오히려 비순차적 실행 범위를 더 넓히고 하나 코어 자체의 성능을 높이는 방향으로 설계되었다. 코어 아키텍쳐는 기존 싱글 쓰레드 기반의 프로세서의 특징, 비순차적 실행 유닛을 그대로 고수하면서도 이를 개선시켜, 각 코어에서 성능을 양보하지 않겠다는 의지가 반영된 것이다. .
즉 이와 같은 접근 구조는 결국, 앞으로 멀티쓰레드 성능이 보장된 애플리케이션에서 높은 성능을 내도록 한 것 이외에도 현재 주류를 이루고 있는 싱글 쓰레드 애플리케이션에서도 탁월한 성능을 낼 수 있도록 한 것이다. 성능에 대해서는 이후에 언급하겠지만 현재 주류를 이루는 싱글 쓰레드 애플리케이션, 특히 게임등에서 컨로가 높은 성능을 낼 수 있는 이유가 여기에 있다. 이러한 이유로 코어 아키텍쳐의 각 코어는 비순차적 실행에 필요한 연산 유닛과 회로를 줄여 다이 크기를 줄이기 보다는 이 특성을 고스란히 유지하면서도 전력 효율이 높도록 구조를 갖추는 방향으로 설계되었다.
그렇다면 펜티엄4와의 넷버스트와 기본적인 차이점은 무엇인가? 넷버스트는 깊은 파이프라인 구조로 클럭 속도를 끌어올리는 것으로 성능향상을 도모할 수 있게 되었지만 코어 아키텍쳐는 칩에 코어수를 늘리는 것으로 성능향상을 도모할 수 있도록 설계되었다. 매 약 18개월마다 트랜지스터 집적수가 2배, 그에 따라서 성능 향상도 이루어진다는 매우 ‘무어의 법칙’스러운 설계이다.