-

-
만들면서 배우는 파이토치 딥러닝 - 12가지 모델로 알아보는 딥러닝 응용법
오가와 유타로 지음, 박광수 옮김 / 한빛미디어 / 2021년 8월
평점 : 


딥러닝으로 문제를 해결하는 과정에서 다른 연구자들의 아이디어 혹은 모델을 활용, 응용, 혹은 변형하는 능력을 키우고 싶을 때 유용한 PyTorch 기반의 실전 교과서라 평하고 싶다.
DNN, CNN, RNN, LSTM 등 딥러닝의 기본을 충실히 익히고 있고 다음 단계로 도약하고 싶은데 마땅한 국내서가 없었다면 이 책이 대안이 될 수 있을거라 생각한다.
새로운 문제 혹은 변형된 문제가 발생했을 때 모델의 입출력 혹은 모듈을 변형하거나, 손실함수를 바꿔본다든가, 다른 분야의 딥러닝 모델을 접목한다든가 등의 실전에서의 응용력을 키우고 싶다면, 더불어 논문 리터러시를 키우고 구현 능력을 키우고 싶다면 이 책이 많은 도움을 줄 것이다.
뇌 기능 측정과 계산 신경과학을 연구한 저자가 연구의 응용력과 구현 기술까지 탁월한데 책의 전달력까지 뛰어나 적잖이 놀랐다. 다른 독자분들의 평도 봐야겠지만 적어도 내 기준에서는 그동안 너무 찾던 책이다.
읽는 내내 컬러판이 아니라는 단점 하나 외에는 모두 장점 투성이였다. 부디 이 책이 널리 흥해서 컬러판이 나왔으면 하는 바램이다.
단, 주의할 점은 난이도가 중급서 이상이라는 점이다. 적어도 python, pyTorch, 딥러닝의 기본(DNN, CNN, RNN, LSTM 등), Linux 정도는 알고 책을 읽는 것이 좋을듯 하다. 처음부터 합성곱층, 전결합층, 텐서보드X 등의 용어가 나오기 때문이다.
각 장별로 어떤 내용을 다루는지 구체적인 설명과 더불어 읽으며 느꼈던 장단점을 기술해보겠다.
들어가기에 앞서 책 소개 챕터에 개발 환경을 구성하는 방법이 나오는데 그동안 봤던 어떤 책보다 실습환경 구성 방법이 자세하게 안내되어 있고 나중에 언급하겠지만 소스 코드들이 오류 없이 잘 실행되고 있어 실습을 따라하는데 편리하다.
1장은 기본기를 훈련하는 단계이다. 가장 크게 5가지 소챕터로 나뉘는데 각각 VGG-16, PyTorch 딥러닝 구현 패턴, 전이학습, AWS활용법, 파인튜닝의 주제를 다룬다. 각 주제들은 하나하나 한 권의 책으로 낼 수 있을 정도로 깊이 있는 주제들이지만 가장 급하게 알아야 할 중요한 요소들만 추려 적은 용량으로 깔끔하게 정리하여 마음에 들었다.
뒤에 이어질 12가지 심도 있는 모델을 이해하고, 구현하고, 응용하는데 있어 반드시 알아야 할 기초 지식이기에 충분히 숙지하고 넘어가야 한다.
첫번째로 Vision 분야의 고전이 되어버린 VGG-16 모델의 구조를 설명하여 독자로 하여금 CNN 등 딥러닝의 기본기와 연결고리를 맺게하여 논문을 읽고 구현할 수 있는 준비를 갖춰준다.
두번째로 PyTorch를 활용한 일반적인 딥러닝 구현 패턴을 설명한다. 딥러닝 실력이 부족하거나 PyTorch 혹은 Tensorflow가 능숙하지 않다면 딥러닝 구현 패턴에 의외로 많은 시간을 낭비하게 된다.
각 논문 구현체나 서적마다 각기 다른 방식으로 구현하고 있기에 혼선이 생겨 직접 구현 시 어떤 패턴을 선택할지 의외로 많은 고민을 하게 되는데 깊게 고민할 필요도 없이 이 참에 이 책에 나온 패턴대로 주류를 잡고 차후 발견하는 패턴을 이 윤곽에서 업그레이드하는 형태로 접근해도 충분히 훌륭한 방식이 될거라 생각한다.
나는 초보자에 지나지 않지만 적어도 지금까지 겪어온 구현체 중에 가장 깔끔하고 확장성이 좋은 패턴이라는 생각이 들었다.
세번째로 전이학습을 다룬다. 앞서 배운 VGG-16 모델을 불러와 출력층만 원하는 형태로 바꾸는 실습을 진행한다. ImageNet 데이터셋과 달리 단순히 개미와 벌을 분류하는 예제이기에 불필요한 부분을 단순화하고 전이학습을 적용하는 방법에만 초점을 맞춘 구성이 마음에 들었다.
네번째로 AWS에서 딥러닝 환경을 구성하고 실습하는 방법을 배운다. EC2 우분투 기반의 인스턴스를 생성한 뒤 P2혹은 P3 인스턴스를 사용하여 손쉽게 딥러닝 개발환경을 구축할 수 있다. 다만 과금이 들어가는 부분이므로 주의해야 하며 다행히 책에서는 실습 시 인스턴스를 중지 혹은 삭제를 꼼꼼하게 가이드하고 있다.
마지막으로 파인튜닝을 다룬다. 딥러닝의 입문 단계를 거쳐 기본 과정에서 가장 많이 듣는 강의 중 하나인 앤드류 응 교수님의 DL Specialization 과정과 비교하자면 그 강의는 전이학습을 좀 간결하게 설명하는 경향이 있어 아쉬웠다. 그도 그럴 것이 전이학습을 넘어서 모델의 전단계에 영향을 미치는 파인튜닝으로 넘어가게 될 경우 설명해야 할 것이 너무 많기 때문이다.
파인튜닝은 새로운 논문이나 모델이 등장할 때마다 수시로 적용해 봐야 하는 마치 Python 문법과 같이 계속 곁에 두고 활용하는 기본 기술이므로 이 참에 이 책을 통해 확실히 익혀두면 실무에 매우 유용할 것이다. 다행히 2장 이후 지속적인 파인튜닝 실습을 진행하는데 이 책 실습만 잘 따라해도 파인튜닝에 꽤 익숙해져 새로운 과제가 주어져도 자신감이 생길만큼 능숙해질 수 있을거라 생각한다.
2장에서부터 본격적으로 비교적 최신 논문에 등장한 아이디어와 모델을 활용한 현실의 문제를 실습으로 해결해본다. 이 장에서는 이미지 Detection에 자주 활용되는 SSD 모델을 중심으로 다룬다. 이 모델을 적용하면 감지를 원하는 물체에 바운드 박스, 라벨, 신뢰도 등을 얻을 수 있다.
구체적으로 SSD300 모델로 실습하며 8,732개의 디폴트 박스, 오프셋 정보변수 4개, 신뢰도 21개 클래스로 218,300개의 정보를 출력하는 실습이다.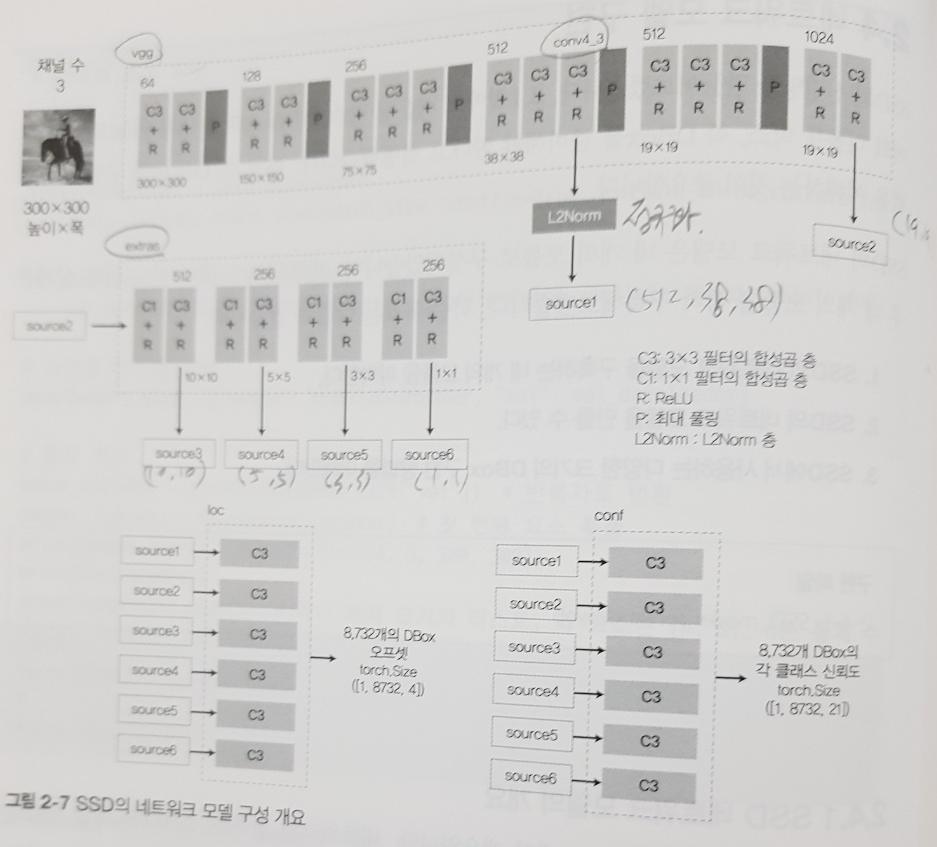
SSD 알고리즘의 핵심은 아래 그림과 같이 디폴트박스(DBox)를 바운딩박스(BBox)로 변형하는 과정이다. 좌측에서 우측 그림으로 변형하며 cx, cy, w, h 등 4개의 오프셋 변수에 관계식이 생성된다. 이를 통해 손실함수 클래스 MultiBoxLoss 클래스를 구현하는 과정이 가장 인상적인데 당면한 문제마다 손실함수만 잘 설계해도 괄목할만한 성과를 얻을 수 있다는 것을 느낄 수 있는 부분이다.

이 책의 겉표지에 왜 “딥러닝 응용”이라는 부제가 붙었는지 알 수 있는 부분이다. 이 책에서 말하는 응용은 구현 기술이라기 보다는 연구 결과를 구현체에 반영하는 과정에서의 응용이니 연구쪽에 가깝다고 할 수 있다. 책에 등장하는 12가지 모델에 잘 훈련된다면 아마 새롭게 마주하는 문제에 있어서도 거인의 어깨에 선 것처럼 기존 좋은 연구나 모델들을 활용하여 멋진 문제를 해결해 낼 수 있겠다는 생각이 들었다.
전체적인 구현 절차는 1장에서 언급했던 기본 패턴을 준수하고 있으며 의외로 디테일한 부분까지 설명하고 있어 친절하다는 느낌을 받을 수 있었다. 1장과 달리 DataLoader등을 직접 구현하기에 새로운 문제에 적합성을 키울 수 있다는 점도 책이 가지는 장점이다.
여담이지만 개인적으로 SSD는 정이 많이가는 모델이다. 몇년 전 SOTA급 논문을 어떻게든 구현하는 능력을 키우고 싶다는 욕망으로 처음으로 달려든 논문이 바로 이 SSD를 발표한 논문이었다. CNN을 배우고 나름의 자신감이 생겨 논문을 뜯어보며 고군분투했지만 당시엔 실패했다.
그 때 실패를 경험하며 삽질을 해서인지 아니면 이 책의 설명이 뛰어나서인지는 알 수 없으나 당시 나를 괴롭혔던 왜 SSD의 디폴트 박스가 8,732개가 나오고 입출력 차원이 원하는대로 계산되지 않았던 것인지 끙끙댈 때와 비교한다면 이 책이 가치를 느낄 수 있다. 이 모델을 처음접하는 독자에게 떠먹여 주는 정도가 아니라 아주 잘게 씹어 떠먹여주는 수준의 친절한 느낌을 받았다.
그렇기에 이 책은 딥러닝의 기본기를 다진 독자가 논문과 접하는 경계선을 탐험하고 스스로의 아이디어를 기존 모델에 접목, 변형해 보고 싶을 때 아주 좋은 무기가 될거라 생각한다.
3장은 PSPNet을 활용한 시맨틱 분할을 배운다. SSD가 무식하게 네모 박스로 감지했다면 얘는 좀 더 정교하게 픽셀 단위 그러니깐 물체의 모양 그대로 경계선을 그려 인식할 수 있다.
이 시점에서 책의 구성이 매우 돋보였는데 2장에서 거의 모든 것을 직접 구현해 기초를 다졌다면, 3장은 파인 튜닝을 활용한다. 뒤에 이어질 4장에서는 일부분을 직접 구현하도록 유도한다.
친절히 모든 것을 알려준 후, 타인의 연구를 응용하는 법을 배우며, 나아가 부족한 부분은 스스로 구현해보게 함으로써 수준높은 학습효과를 달성할 수 있다. 다른 이들은 어떨지 모르나 개인적으로 너무 마음에 드는 구성이다.
4장은 OpenPose 모델을 다루는 데 쉽게 말해 사람 이미지를 탐지할 경우 뼈다귀 형태의 사람을 추출하는 기술이다. 대략적인 방식은 아래 그림을 참조하기 바란다.
이 장에서는 PAFs와 히트맵이 이 모델의 성능을 정교하게 끌어올리는 부분이 관심있는 부분이었다. 확실히 Vision 분야의 데이터여서 그런지 XAI 기법도 가능하고 해석력이 높은 모델인 점에 끌렸다.
5장은 GAN을 다룬다. 먼저 전통 GAN모델의 대표주자인 DCGAN으로 MNIST와 유사한 손글씨를 생성한 후 SAGAN에 대해 깊숙히 살펴본다.
이 장의 핵심은 Attention 모델이다. 특히 304p의 설명은 참 알기쉽게 잘 쓰여있다는 생각이 들었다. 원론, 수학적으로 크게 부족한 내용없이 소스 코드 구현과정을 통해 명확하게 이해할 수 있게 쓰여있어 인상적이었다. 더불어 308p의 스펙트럴 정규화도 참 알기쉽게 설명을 잘하고 있어 논문이나 교과서의 내용이 어렵다면 이 책을 통해 진입장벽을 낮춰 접근하는 것도 좋은 방법이 되리라는 생각한다.
6장은 AnoGAN이 메인 주제이다. 정상데이터에 대한 모델 학습 후 판별자 뿐만아니라 생성자도 활용하여 이상 이미지를 검출하는 방법을 다룬다.
이 장 역시 앞서 언급했던 손실함수 변형을 통한 문제 해결 능력을 키워주는 부분이 장점인 파트이다. 구현만이 아닌 이론, 수학적 차원에서 고민을 해결하고자 할 때 저자의 접근방식에서 힌트를 얻을 수 있을 것이다.
7장 ~ 8장은 NLP를 다루는 데 특히 Transformer, BERT가 핵심이다. 이를 통해 자연어 감정분석을 다루는데 5장의 Self-Attention에 이어 Attention이 언어에 어떻게 적용되는지 또 한 번 Attention의 본질과 응용 방법을 익히기 좋은 장이다.
문맥과 어순 즉, Sequence여야한다는 NLP의 고정관념을 깬 아이디어가 어떻게 BERT까지 이어지게 되었는지 논문 리뷰하듯 상세히 분석해주는 것이 장점이다.
단, 일본어를 예제로 다루고 있어 일본어 지식이 전무한 나같은 독자는 예제를 쉽게 이해하기 힘든 것이 단점이지만 그럼에도 Attention과 BERT의 핵심을 너무 잘 전달하고 있어 반드시 읽어둬야 하는 파트이다.
마지막 9장은 ECO 모델이 등장한다. 이는 동영상을 분류하는 알고리즘인데 마지막 장이어서인지 학습이나 파인튜닝의 소스는 독자 스스로 구현해봐야 한다. 앞서 언급한대로 개인적으로 매우 마음에 드는 구성이다.
이 모델은 2차원 CNN으로 작은 크기의 피처를 추출한 뒤 C3D 모델에 입력하는 것이 핵심이다. 아직 구현해보지 않았는데 공부도 조금 더 필요하고 아껴두는 마음으로 남겨뒀다. 이 장에서 스스로의 구현 능력을 얼마나 완성시킬 수 있느냐에 따라 앞으로의 새로운 연구의 구현, 응용의 미래가 달려있다 생각했기 때문이다. 일종의 시험치르는 느낌이었다.
책을 읽으며 워낙 배운 것도 많고 느낀 것도 많아 쓰다보니 리뷰가 너무 길어진 것 같다. 내용이 너무 길어지는 듯 싶어 써가며 나름 핵심만 남기고 줄였음에도 이렇게 길어질 정도로 이 책에서는 배우고 느낄만한 점이 정말 많다.
서두에 언급했듯 근래에 보기드문 중급서 교과서가 등장했다. 나 혼자만의 의견일진 모르겠지만 적어도 내겐 핸즈온 머신러닝, 머신러닝교과서, 밑바닥 시리즈 등과 비교해도 손색이 없을 정도의 완벽한 책이라는 생각을 했다.
거인의 어깨를 빌려 배우고, 응용하며 자신만이 가진 문제를 딥러닝으로 해결하고 싶다면 혹은 그 단계로 나아가기 위해 기초 수준에서 어려움을 겪고 있다면 강력히 추천하고 싶은 책이다.