-

-
GAN 첫걸음 - 파이토치 신경망 입문부터 연예인 얼굴 생성까지
타리크 라시드 지음, 고락윤 옮김 / 한빛미디어 / 2021년 3월
평점 :

절판

GAN(Generative Adversarial Network, 생성적 적대 신경망)은 서로 경쟁하는 두 개의 신경망(생성자, 판별자)으로 구현된다. 생성자는 새로운 데이터를 생성하며, 판별자는 가짜와 실제를 구별한다. 생성자와 판별자는 서로 이기려는 경쟁을 지속하는데 위조범이 그럴듯한 모조품을 만들면 판별자가 잡아내는 식의 경쟁이다.
말이 쉽지 GAN을 배우려고 책을 펴면 이상한 것들을 새로 배워야 한다. 오토인코더 부터 시작해서 G와 D가 팽팽하게 서로 당기고 있는 이상한 긴 수식, Likelihood에서 부터 각종 확률과 분포 등등..
반면 이 책은 GAN을 처음 접하거나 어려워 포기했던 이들에게 제 격인 책인 것 같다. 내 기억이 맞다면 오토 인코더라는 말은 한마디도 안나왔다. 대표적으로 눈에 띄는 장점을 정리하면 다음과 같다.
GAN의 핵심을 3단계로 정리하고 예제로 구현하는 부분은 그 어느 책보다도 전달력이 뛰어났다.
반드시 필요한 것만 간추려 알려주고 있어 완급 조절이 훌륭한 책이다.
계보(AE, VAE, GAN, DCGAN, MMGAN, NSGAN, WGAN, WGAN-GP, ProGAN, SGAN, CGAN, CycleGAN, RGAN, SAGAN, BigGAN에 이르는…) 흐름이 아닌 모드 붕괴, 경사하강법 등 문제 인식에 초점을` 맞춘 접근법이 마음에 들었다.
난이도는 쉬운 반면, 다루는 깊이는 논쟁이 되고 있는 연구까지 다루고 있다.
아마도 GAN, 딥러닝, PyTorch 셋 다 몰라도 이 책이라면 무난히 GAN의 세계에 입성할 수 있을 것 같다. 정말 쉽다.
간단한 장점만으로는 설명이 부족한 것 같아 전체적인 구성 및 책을 읽으며 인상깊었던 핵심 내용들을 위주로 아래와 같이 정리해 보았다.
파트 1 : 준비과정
먼저 PyTorch와 Colab의 기초를 배운다. Define By Run 방식의 계산 그래프를 토대로 자동 미분을 실습하는 과정을 통해 PyTorch의 활용법과 직관적인 장점을 느낄 수 있다.
다음으로 MNIST 손글씨 분류 신경망을 만들어 본다. Pandas와 Matplotlib으로 MNIST 데이터가 어떻게 생겼는지 열어본 후, 기본적인 네트워크를 구성한다. 오차를 정의하는 손실함수, 가중치 학습 방법인 옵티마이저, train() 함수 등을 만들며 신경망의 기본을 다진다.
이어서 만든 모델의 성능을 단계적으로 아래와 같이 향상시킨다.
- 손실함수 : MSE -> BCE
- 활성화함수 : Sigmoid -> LeakyReLU
- 옵티마이저 : SGD -> Adam
- 정규화 적용 : LayerNorm()
위 단계를 거쳐 모델의 성능을 87%에서 97%까지 끌어올리는데, 딥러닝의 성능 개선을 위한 일반적인 방법을 핵심만 잘 간추리고 있다.
다음으로 CUDA는 어떻게 활용하는지, 성능은 얼마나 향상되는지 측정해본다.
- Vectorization : Python(for) ->
Numpy(행렬) / 1500배 성능 향상 - CUDA : Numpy(CPU) ->
CUDA(GPU) / 150배 성능 향상
파트1은 정리하자면 딥러닝과 PyTorch의 기본을 복습하는 장이다. 이미 둘을 잘 알고 있다면 건너 뛰어도 무방하다.
하지만 스스로 딥러닝이 부족하다고 느껴진다면 반드시 꼼꼼하게 익히고 넘어가야 한다. 판별자가 딥러닝 모델과 거의 유사하기 때문이다. 판별자도 제대로 만들기 어렵다면 더욱 까다로운 생성자 혹은 판별자와 생성자 간 통신을 이해하기 어려울 것이다.
GAN을 배우고 처음으로 맞닥드렸던 난관이 모드 붕괴였는데 아마 대부분 공통적으로 겪는 현상이 아닌가 싶다. 뒤에 이를 해결하기 위해서 딥러닝의 성능 개선 방법을 미리 익혀두는 것은 필수이며, 이를 확실히 알기 위해서는 딥러닝의 기초가 필수다. 또 이를 위해 PyTorch이나 Colab 실습 환경 사용법을 숙지해야 함은 말할 필요도 없다.
이처럼 큰 집을 만들기 위해 초보자들도 쉽게 따라할 수 있도록 벽돌을 아래부터 하나씩 차곡차곡 쌓아올리는 구성이 인상적이었다.
파트3 : 합성곱과 조건부 GAN
이 파트에서는 GAN의 품질을 조금 더 높힐 수 있는 방법들을 다룬다. CNN을 활용하는 DCGAN, 메모리 공간복잡도 측정법, GELU 활성화 함수가 소개된다.
특히, CNN의 구조를 직관적으로 잘 설명하고 있고 - 왠만한 딥러닝만 집중으로 다루는 책보다 훨씬 낫다 - 부록에서는 CNN 네트워크 설계 방법과 관련된 Tip을 다루고 있다. 예전에 들었던 앤드루 응 교수님의 코세라 대표 강의 Deep Learning Specialization보다도 핵심을 더 잘 요약했다고 생각한다.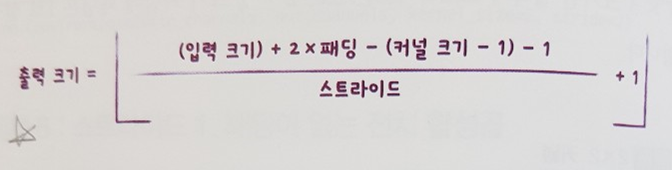
CNN의 적용한 결과 위 얼굴이미지 예제에 비해 윤곽선이 또렸해 졌음을 확인할 수 있다.
이어서 조건부 GAN 파트에서는 레이블과 Input 관계를 학습하는 것에 초점을 맞춰 특정 레이블에만 조건부로 집중하여 품질을 향상시켜 본다.
마지막으로 부록에서는 위에 언급한 것들을 제외하고도 GAN의 우도 학습이나, f = xy 같은 심플한 함수로 불안정한 학습과 경사학습법의 한계를 다룬다. GAN의 심화 단계로 넘어가기 위한 필수 개념들을 심플하게 잘 전달하고 있다.
끝으로 대부분의 기술서들과 달리 열정만 있으면 실력이 없어도 익힐 수 있는 차별화된 장점을 갖춘 멋진 책이라는 점을 강조하며 리뷰를 마친다.