-

-
파이썬 라이브러리를 활용한 데이터 분석
웨스 맥키니 지음, 김영근 옮김 / 한빛미디어 / 2023년 5월
평점 : 


데이터 분석이나 AI 분야에 필요한 Python을 활용하는 기법의 핵심만 잘 정리한 책으로 여러 대학의 교과서로 채택된 만큼 관련 목적으로 가장 먼저 읽을 것을 권하고 싶은 책이기도 하다.
데이터 과학이 세간의 정의대로 “프로그래밍 + AI + 도메인”의 융합 분야라 가정한다면 이 책은 그 중 프로그래밍의 스킬을 습득하는 데 큰 도움이 되는 책이다.
AI분야에서 가장 인기있는 언어는 Python이며 Python의 기본 문법은 물론 라이브러리를 쉽고 빠르게 익히고 싶다면 가장 먼저 이 책을 읽을 것을 추천하고 싶다. 개인적으로는 몇년 전 2판을 보고 매우 큰 도움을 얻을 수 있었다. 이미 세계 유수 대학에서 교재로 활용되고 있거니와 AI 분야에 처음 진입하는 입문자에게 추천이 끊이지 않는 책이기도 하다.
2판과 기본적인 내용은 매우 유사하다. 다만, Python 3.11의 최신 버전을 기준으로 예제 코드들이 작성되어있다는 점이 다른 부분이다. 아무래도 2판은 3.6 버전이었기에 그새 추가된 편의 기능이 상당하다. 기타 부록이나 groupby와 내용 등 부분적으로 내용이 풍부해진 점도 눈에 띄였다.
기본적인 책의 내용 및 이 책만이 가지고 있는 특징을 중심으로 간단하게 책을 소개해보고자 한다.
우선 1 ~ 3장은 Python의 기초 지식에 대해 설명한다. Python의 현 위치, 기초 문법 및 내장 자료구조, 주피터 노트북을 다루는 방법이 소개되어있다.
Python은 R과 같은 특수목적 언어가 아니라 범용 언어이기 때문에 연구 및 포팅 과정을 분리할 필요없고 Glue 코드로 C언어와 같은 저수준 호환이 가능하여 데이터 분야에 지속적인 성장중이라는 사실과 GIL과 같은 단일스레드 특성 그 외에도 오늘날 Python의 위상을 가능케한 강력한 라이브러리 - Numpy, Pandas, SciPy, scikit-learn 등 -의 개요를 소개하고 설치 및 간단한 예제를 실습한다.
이어서 Python 실습 환경 중 가장 애용되는 주피터 노트북을 실습한다. “?”를 통해 객체의 정보를 얻는 등의 팁도 소개되어있다. 맨 뒤 부록편에 IPython의 심화과정이 이어지니 이미 주피터 노트북을 많이 다뤄본 독자라면 부록편을 먼저 읽는 것도 나쁘지 않을듯하다.
부록편에는 알아두면 매우 유용한 단축키, 매직명령어, 명령어 히스토리, 북마크 기능 등이 소개되어있어 제대로 익히면 개발 속도를 몇 배는 높일 수 있을 것이다.
개인적으로는 대화형 디버깅 및 프로파일링 기능에 대한 소개가 큰 도움이 되었다. 간결한 예제로 그대로 따라하니 쉽고 빠르게 주피터 환경에서의 디버깅이 가능했다. 그동안 이 방법을 잘 몰라 Pycharm에 크게 의존했었는데 이제 툴 가리지 않고 이런 편리한 기능을 습득할 수 있어 만족스러웠다.
1 ~ 3장의 가장 만족스러운 부분은 Python의 기초 문법과 내장 기능을 매우 잘 정리한 것이다. 자주 활용되는 예제로 매우 빠르게 습득할 수 있게 구성되어있고 특히 자주 실수하는 부분 다른 언어와의 다른 특성으로 인해 개발자들이 실수하는 부분을 중심으로 핵심만 매우 잘 뽑아냈다는 생각을 들게 했다.
isinstance(), iter(), is, pass, range() 등 Python의 독특한 기능들이 확실히 구별하여 익힐 수 이게 잘 구성되어있고, 튜플이나 리스트 자료형에서 *_로 불필요한 변수를 버리는 관습, 슬라이싱 및 step, items()와 zip(), 중첩 리스트 컴프리헨션, 다중 값 반환, 제너레이터 등의 기능이 소개된다.
묵직한 기본서로 착실히 기본 문법을 습득하는 것도 중요한 일이지만 다른 언어에 정통한 경력자 같은 경우 이 책에서 소개하는 정도로만 빠르게 문법을 익히고 AI 프로젝트에서 필요 시 마다 문법을 찾아 적응하는 top-down방식도 나쁘지 않은 습득방식이라 생각한다.
4장 이후로는 본격적인 데이터 분석에 필요한 기법들이 소개된다. 4장은 NumPy가 소개되는데 선형대수 및 행렬 연산을 위해 데이터 분석에서 가장 많이 쓰이는 라이브러리 중 하나이다.
사실상 5장 이후로 대부분 가독성 좋고 분석가 지향의 Pandas를 주로 사용하지만 간간히 데이터 변환을 위해 Numpy를 사용하는데 이를 위해 필요한 최소한의 연산 기법만 소개하고 있다.
그 수준을 벗어나는 내용은 부록A에 따로 정리되어있다. 비록 부록에 들어있지만 대부분의 실전에서는 오히려 부록에 있는 내용들이 더 많이 활용된다.
자주 활용하다보면 중요성을 알게 하는 stride 개념과 브로드캐스팅, 타 언어와의 호환, ufunc 메소드 및 성능에 관한 팁 등이 소개되어있는데 특히 타 언어의 호환이나 성능과 관련된 조언은 향후 많은 도움이 될 것 같다.
어쨌든 4장에서 소개하는 NumPy는 기본적인 행렬 연산 및 Vectorization이라 흔히 칭하는 반복문을 피하는 방법 정도만 소개되어있어 쉽고 빠르게 익힐 수 있다.
5장은 이 책의 가장 중요한 라이브러리인 Pandas를 소개한다. 이 책이 다루는 대부분의 데이터 형태는 tabular이기에 가장 많이 활용되는 라이브러리는 Pandas가 된 것 같다. 비정형은 대부분 딥러닝의 영역이고 일반적인 데이터 분석과는 다른 영역으로 인식하기에 딥러닝과 직접적으로 관련된 부분 - 텐서플로, 파이토치, 비정형데이터 등 - 은 다뤄지지 않는다.
tabular 데이터 - 이 책은 structed data 라고 표현한다. - 는 대부분 우리가 일상에서 가장 접하기 쉬운 구조를 갖고 있다. 즉, 엑셀이나 보고서에서 흔히 보는 표 형태의 데이터라고 생각하면 이해하기 쉬울 것이다. Pandas는 이런 형태의 데이터를 가공, 분석하는데 굉장히 편리한 기능을 제공한다.
5장은 Series, DataFrame의 사용법을 주로 다룬다. loc, iloc을 통한 접근 및 색인 방법이나 apply를 통한 가공 그리고 기술 통계를 위한 활용법을 다룬다.
앞서 기초 문법 영역에서도 언급했지만 기본 문법을 배우고 실전에서 흔히 겪는 문제들을 미리 언급해 둔 부분이 마음에 든다. 예를 들어 연쇄 색인이나 정수 색인의 함정을 언급한 파트가 그러하다.
다른 기본서를 통해 문법을 익혔을 때는 대부분 그런 설명이 없어 실전에서 꽤 시간을 소모하거나 당황한 적이 있는데 이 책은 기본 지식만 전달하는 것 이상으로 흔히 발생할 수 있는 오류나 부가 설명이 함께 설명되어 있어 실전에서의 시행착오를 크게 줄여준다.
결국 Pandas등으로 데이터 분석을 한다고 해도 결국은 DB, File등으로 부터 데이터를 I/O하는 것은 피할 수 없는데 6장에는 그런 입출력에 관한 정리가 담겨있다. read_csv로 읽어들이거나 읽는 방식이나 옵션을 제어하는 방법들이 기술되어있다. 특히 beautifulsoup 등을 이용해 웹 스크레이핑하는 방법 및 XML, DB와의 IO도 간략히 소개되어있다.
7 ~ 8장, 10장은 전처리에 주로 활용되는 데이터 정제, 가공에 자주 쓰이는 기법들이 소개되어 있다. 결측치를 제거하거나 대체하는 방법, 샘플링, 더미화, Join, Merge, groupby 등의 기법이 그러한 예이다.
개인적으로 SQL에 친숙해진 나의 경우 Python의 유연함이 오히려 독이었다. 같은 2차원이라고는 하지만 SQL의 경우 열에 해당하는 차원은 유일하며, 고정이었기에 다양한 인덱스 및 열이 존재하는 DataFrame 객체는 가공하기 은근히 까다로웠다.
reset_index, set_index, drop 등의 기능을 이 책을 통해 쉽게 익히고 개념을 잡을 수 있었다. 새롭게 알게된 가공 기술은 SQL때 하지 못했던 세부적이고 정밀한 가공을 가능하게 해줘으니 이 부분 또한 이 책에 가장 고마운 부분 중 하나이다.
9장은 matplotlib이나 seaborn을 활용한 기본적인 시각화를 다룬다. 산포도나 히스토그램 등 가장 흔하게 사용하는 형태 몇가지를 범례, 축, 주석, 눈금 등을 셋팅하는 수준으로만 다루고 있어 그 이상의 정보는 필요할 때마다 다른 전문도서를 참조하는 것이 좋다. 뒤에 13장에 여러 실전 프로젝트 예시가 등장하는데 그때 이해할 수 있는 수준의 지식 정도만 다루고 있다.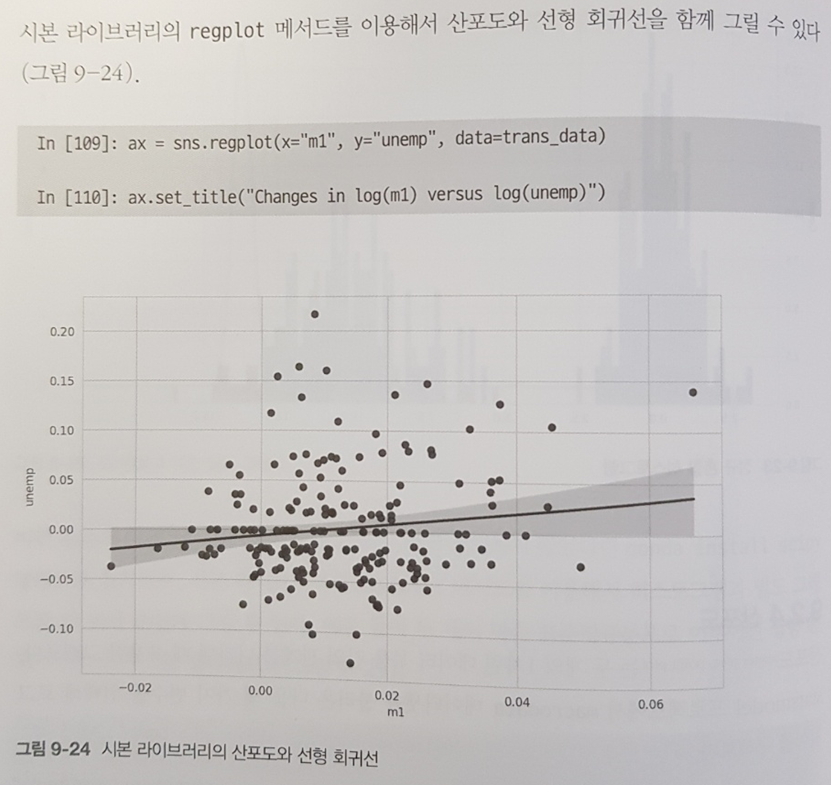
11장은 시계열과 관련된 데이터 가공, 연산 기법을 다룬다. datetime, timedelta 등으로 다양한 예제를 처리하다보면 금방 감이 온다. 시간 데이터가 들어오면 데이터 가공은 정말 까다로워진다.
특히, 날짜를 시프트하거나, 서로 다른 타임존을 일치시킨다거나, 리샘플링, 이동평균값 산정 등에 있어서 까다로운 편인데 예전에 Pandas의 기능을 충분히 알지 못해 직접 일일이 기능을 개발했던 경험이 있다. 이후 Pandas가 제공하는 편리한 라이브러리를 활용하고 나서 시계열은 되려 SQL로 처리하지 못하게 되는 불상사(?)가 일어나기도 했다.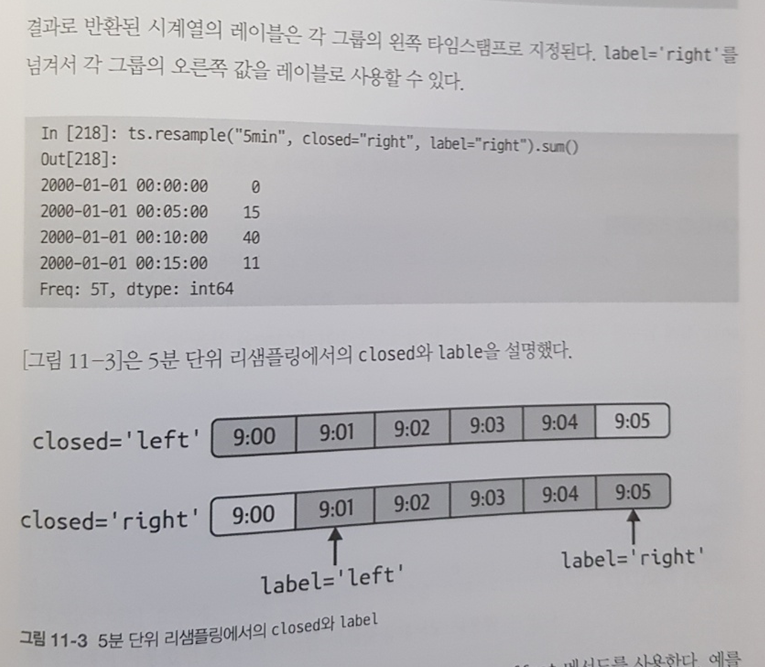
아무튼 이 책은 그간 시계열을 통해 겪었던 매우 잦은 시행착오들을 번복하지 않도록 필요한 기능을 잘 추려 설명하고 있다는 점이 또 하나의 장점이다.
12장은 전통 통계기법 라이브러리인 statsmodels로 기본 모델링을 하는 방법을 다룬다. 솔직히 개인적으로는 statsmodels를 실전에서 써 본 경험이 없다. 데이터가 대용량으로 축적되고 나서 전통적인 통계 모델을 효용가치가 많이 줄어든 것 같다.
물론 사이킷런이나 딥러닝 프레임워크의 비약적인 발전과 비정형 데이터에서의 뛰어난 성능이 statsmodels를 더욱 소외받게 만든 이유도 있는 것 같다.
빅데이터, AI 시대에 엄밀함과 추정 및 검정은 확실히 중요도가 줄어든 면은 있지만 어쨌든 이 책에서는 데이터 분석이나 모델링 보다는 Python 기술을 익히는데 초점을 맞추고 있기에 목적에 충실하고자 간단한 모델링의 샘플을 보여주고자 이 챕터를 수록한 것 같다.
13장은 본격적으로 지금까지 배운 기술들을 종합하여 실전 데이터 분석을 진행해본다. 가급적이면 각 예제를 대충 살펴보고 궁극적으로 원하는 데이터가 무엇인지 살펴본 후 책을 참조하지 않고 직접 분석 작업을 진행해 볼 것을 권한다.
1 ~ 12장을 익혀 꽤나 자신감을 얻었음에도 실전 문제를 푸는 것은 정말 녹록치 않음을 느낄 것이다. 그러한 깊은 고민이 거듭된 뒤 이 책의 예제를 통해 해결책을 찾는다면 그동안 배운 파편화된 지식들이 연결되는 느낌을 받을 것이고 실전에서 강력한 문제해결 능력을 갖게 도와줄거라 생각한다. 개인적으로는 그런 방법으로 많은 도움을 받았다.
책 내용 외 구성상의 특징으로는 개인적으로 빛 번짐 방지 처리가 된 것이 너무 마음에 들었다. 한빛미디어 책은 거의 모든 것이 늘 마음에 들었는데 딱 한가지 아쉬운 부분이 가끔 종이 재질에 따라 형광등에 빛이 반사되어 책이 잘 보이지 않는 현상이 있었는데 이번 책은 번짐 현상이 전혀 없어 집중해서 편안하게 읽을 수 있었다.
또, 비록 이번 판이 컬러 인쇄판은 아니지만 시각화는 1개 챕터만 차지하고 있고 그 외 내용은 음영처리로도 충분히 시각적으로 이해하는 데 문제가 없었기에 오히려 흑백으로 인쇄하여 보다 저렴한 비용으로 많은 독자들이 읽을 수 있는 기회를 얻는 것이 좋다고 생각한다. 이런 저런 측면에서 내용 뿐만아니라 구성상으로도 100점을 주고 싶을 만큼 마음에 쏙 드는 책이다.
언제고 이 책을 꼭 한 번 리뷰해보고 싶었지만 수 년간 엄두도 못내다가 이번 3판 발간을 계기로 쭉 한 번 정리해볼 수 있어서 즐거웠다. 리뷰가 너무 길어져 독자분들이 참조하시기에는 불필요한 말들이 너무 많아졌지만 700페이지에 육박하는 책을 그래도 조금 자세히 들여다 보는 계기를 만들고 싶은 욕심을 양해해주시기 바란다.
아무튼 AI, 데이터 분야에 Python을 활용하기로 마음을 먹고 진입하기로 결정했다면 가장 먼저 읽을 것을 추천하고 싶은 책은 이 책이다. 그 외 필요한 것들은 해당 분야에 정통한 책을 읽어가면 자연스레 살이 붙게 될 것이다. 더불어 AI나 모델, 통계, 수학에 능숙하지만 Python 프로그래밍이 두려운 분들이 쉽게 Python에 정착하는데도 이 책은 많은 도움을 줄 수 있을것이다.