-

-
소프트웨어 스펙의 모든 것 - 프로젝트를 성공으로 이끄는 소프트웨어 스펙(SRS) 작성법
김익환.전규현 지음 / 한빛미디어 / 2021년 1월
평점 :



개인적으로 프로젝트에 돌입할 때마다 스펙이라는 문서를 읽고 쓸 기회를 접하며, 덕질하는 시간에는 오픈 소스 문서 번역등에 기여해 본 경험이 있기에 언제고 기회가 되면 소프트웨어 스펙 작성법에 대해 진지하게 배우고 고민해봐야 겠다는 생각을 했는데 마침 적합한 책이 등장하여 리뷰를 남긴다.
본 책의 메인 주제인 SRS란 소프트웨어 요구 명세를 의미하며 스펙이라고도 부른다. 구체적인 실체를 알고 싶다면 아래 링크를 클릭하여 저자가 소개하는 템플릿을 다운로드 하여 확인하기 바란다.
SRS Template 다운로드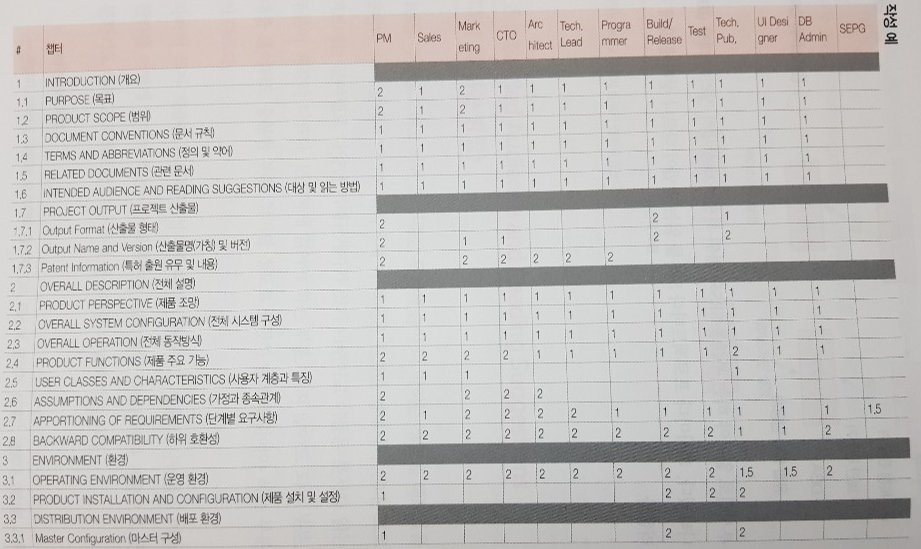
이 책은 SRS를 작성하는 방법을 다루는 책으로 Who, What, How 등 다각도에서 고민해보며 기업 문화까지 스펙에 녹이고자 노력하는 진솔함이 돋보이는 책이다.
저자는 2000년 초반에 출간된 “대한민국에는 소프트웨어가 없다.” 책의 저자이기도 하다. 당시 대한민국의 찍어내기식 사농공상 문화에 회의를 느꼈기에 책을 읽으며 많은 생각을 하였다.
S/W 중심의 대한민국의 경쟁력 향상을 위해 개발자, 정부, 기업 등에 강한 일침을 가한 내용이 인상적이었는데 20년 가까이 지나 당시의 조언에 실리콘밸리식 문화와 커리어가 가미된 본 도서를 읽게 되니 감회가 새로웠다.
컴퓨터 공학을 전공한 사람이라면 대부분 소프트웨어 공학 만큼 재미없는 전공 과목을 찾기도 어려울 것이다. 코딩을 통해 눈으로 결과를 보는 과정도 없고 실무 경험도 전무한 대학생이 사상 누각 형태로 장님이 코끼리 다리 만지듯 저 위에 떠 있는 실체없는 공학을 이해하고자 노력하는 것은 정말 답답한 노릇이 아닐 수 없다.
문제는 이 현상이 기업에 입사하여 시니어가 되어도 지속된다는 점에 있다. 하나의 프로젝트를 모두 총괄하는 사람이 되어보기 전까지는 이런 총체적인 눈을 필요로 하지 않기 때문이다. 게다가 경험 미숙으로 스펙에 대한 내용이 구체적으로 와 닿을리도 만무하다.
그런 측면에서 본 도서는 스펙을 작성하는 일이 따분함을 넘어서 왜 어려운지, SRS의 실체는 무엇인지 설명하기 위해 많은 지면을 할애한다.
스펙에 대한 회사 구성원의 오해는 어떤 것들이 있는지, 스펙과 유사한 설계 및 요구사항과의 차이점은 무엇인지, 현재 스펙과 관련된 악습과 관행은 무엇인지, 기업 문화가 스펙에 왜 반영되어야 하는지, 스펙을 제대로 작성하지 못해 발생하는 실제 사례들은 어떤 것이 있는지 살펴본다. 2부에서는 실제 사례를 중심으로 SRS를 작성하는 예시도 소개된다.
스펙이 작성하기 어렵다는 것은 저자도 충분히 공감하고 인정하기에 이를 작성하는 딱딱한 매뉴얼에서 벗어나 예시, 차이, 관점의 변화, 기업 문화, 영향 사례를 다각도로 짚어보며 스펙을 최대한 알기 쉽게 설명하고자 노력한 점이 책의 백미이다.
이 책에는 SRS의 작성법 외에 또 다른 가치가 숨어있다. PM, 아키텍트 이상의 관리자에게 필수적인 프로젝트가 실패하는 이유, SRS를 통해 소프트웨어를 최단 시간 내 개발하는 법, 기업 문화와 사람 관리에 대한 방법에도 포커싱을 맞추고 있다.
사실 이 모든 내용들이 올바른 방향으로 선행되어야 의미있는 SRS를 작성할 수 있음을 강조하고 있다. 그저 작성 요령만 갖출것이 아니라 개발문화, 관행, 습관, 프로세스, 원리, 원칙들이 모두 녹아있어야 좋은 SRS를 작성할 수 있다는 의미이다.
SRS의 중요성을 인식하기 위해 책에서 제시하는 여러 예시 중 특히 인상 깊었던 것 2개를 꼽아보려 한다. 하나는 모든 프로젝트 이해관계자를 연결하는 중심이라는 점이다. 이 덕분에 제품이 완성되지 않아도 영업팀은 사전 판매에 돌입할 수 있으며, 인증도 사전에 취득할 수 있게 된다.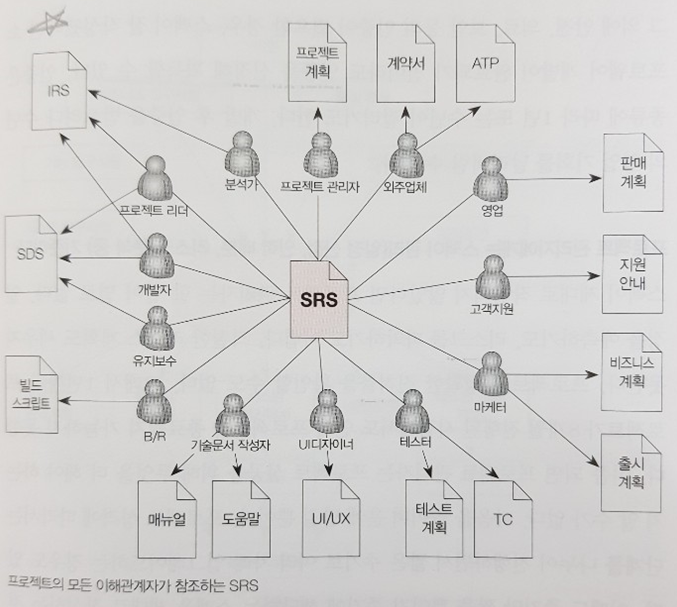
다음은 1:10:100 규칙에 대한 설명이다. 스펙이 변경될 경우 요구분석 단계에서의 비용이 1이라는 가정하에 유지보수 단계로 넘어갈수록 200배에 가까운 비용이 낭비된다. 시간이 흐를수록 얼마나 큰 비용이 발생하는지 구성원 전부 명확히 인식할 필요가 있으며, 그렇기에 스펙이 정확히 작성되어야 하는 것이 얼마나 중요한지를 보여주는 사례이다.
가장 인상깊었던 파트는 6장(프로세스)과 9장(How) 파트이다. SRS를 작성하는 매우 구체적인 방안과 예시가 소개되고 있으며 코드 리뷰처럼 스펙을 리뷰하는 방법이나 협업의 방향을 다루고 있어 조직의 발전을 위한 방향을 엿볼 수 있다.
더불어 소스코드 및 유닛 테스트를 통한 스펙을 작성하는 실전법이나 인터페이스 개선 및 정의 부분은 수십년 간 경험을 축적한 저자의 내공을 느낄 수 있는 파트였다.
10장 도구 편에는 SRS를 작성하는데 도움이 되는 툴들이 소개되는데 미처 몰랐던 유용한 Tip들이 다양하게 소개되어 있어 실전에 유용하게 사용할 수 있다.
2부에서는 SRS 작성을 위한 구체적인 예시가 등장한다. 1부에서 익힌 감에 현 직장의 문화를 더해 실전처럼 적용해 볼 수 있는 구성이 마음에 들었다. 다만 한가지 아쉬운 점은 하나의 특정 개발 사례를 중심으로 일관성있게 소개되었다면 더욱 템플릿을 이해하기 쉽지 않았을까 싶다.
소프트웨어 공학에 대한 책 중 이론을 설명하거나 번역서는 그래도 자주 접할 수 있다. 하지만 국내 저자가 국내 정서를 반영하여 작성했다는 점, 지극히 실전적이고 구체적인 예시를 든다는 점, 수십년 간의 전문적인 커리어가 반영되었다는 점에서 이 책은 관련 서적 중 매우 귀중한 희소성을 띈다 할 수 있다.
PM, 아키텍트 이상의 관리자에게는 SRS 작성법은 물론 프로젝트의 성공과 올바른 기업 문화의 정착을 위해 필독서일 것이다.
그 외 구성원에게 있어서도 이론으로만 존재했던 소프트웨어 공학의 실체를 느끼고, 개발 및 조직 문화를 이해하며, 프로젝트의 일원으로서 커뮤니케이션 능력을 향상 시키는데 도움이 되므로 어느 정도의 경험이 쌓인 개발자라면 반드시 일독할 것을 권하고 싶다.
소프트웨어, Sw, 스펙, Srs, 사례연구, 기업문화, 프로세스, 도구, 체크리스트, 인터페이스, 프로세스, 프로젝트
|