
OCR, 음성 인식, 구조화된 데이터 출력 등 ‘정답이 정해진 작업’에 특화된 새로운 AI 모델 아키텍처 ‘Interfaze’ 가 공개되었습니다. AI 기업 Interfaze가 발표한 이 모델은 대규모 언어 모델(LLM)보다 높은 정확도와 낮은 비용으로 정형화된 작업을 처리하는 것을 목표로 합니다.
공식 블로그에 따르면, Interfaze는 Gemini-3-Flash, Claude-Sonnet-4.6, GPT-5.4-Mini, Grok-4.3 등 경량·고속 모델과 비교하여 OCR, 이미지 인식, 음성 인식, JSON 출력 등 9가지 벤치마크에서 높은 성능을 기록했습니다.
Interfaze: A new model architecture built for high accuracy at scale - Interfaze
https://interfaze.ai/blog/interfaze-a-new-model-architecture-built-for-high-accuracy-at-scale https://interfaze.ai/blog/interfaze-a-new-model-architecture-built-for-high-accuracy-at-scale

기존 LLM의 한계와 Interfaze의 접근법
인간은 문서를 읽고 의미를 이해하거나 모호한 지시를 해석하는 데 능숙하지만, 50페이지 분량의 PDF를 한 글자씩 읽고 각 단어의 좌표를 기록한 뒤 다른 언어로 번역하는 작업에는 적합하지 않습니다. 시간이 오래 걸리고 실수가 늘어나며 비용도 높아집니다.
Interfaze의 설명에 따르면, 현재 널리 사용되는 Transformer 기반의 대규모 언어 모델도 비슷한 특성을 지닙니다. 즉, 문맥 이해와 창의적 처리에는 강하지만, OCR이나 데이터 추출처럼 정확성과 재현성이 요구되는 작업에서는 인간과 유사한 오류가 발생하기 쉽습니다.
이에 Interfaze는 DNN(심층 신경망)이나 CNN(합성곱 신경망) 같은 작업 특화형 신경망과 Transformer 디코더를 결합한 하이브리드 구조를 채택했습니다. DNN과 CNN은 OCR, 번역, GUI 검출 등 특정 작업에 최적화하기 쉽고, 글자의 위치 정보나 신뢰도 점수 같은 메타데이터도 출력할 수 있습니다. 반면, 단독으로는 유연한 추론이나 언어적 판단이 어렵습니다. Interfaze는 이 약점을 Transformer로 보완하여, 정형화된 작업의 정확성과 LLM의 유연성을 동시에 확보하려는 설계입니다.
아래 그림은 Interfaze가 입력을 처리해 출력을 생성하는 과정을 보여줍니다. 프롬프트는 전처리를 거쳐 DNN·CNN과 Transformer가 결합된 핵심 부분으로 전달되며, OCR, 객체 검출, 번역, 음성 인식 등 작업별 어댑터와 연동됩니다. 이후 필요한 정보만 정리되어 디코더나 구조화 출력 모델을 통해 텍스트나 JSON으로 출력됩니다. 이 구조는 Interfaze가 ‘전문 모델의 정확성’과 ‘Transformer의 유연성’을 결합하도록 설계되었음을 보여줍니다.
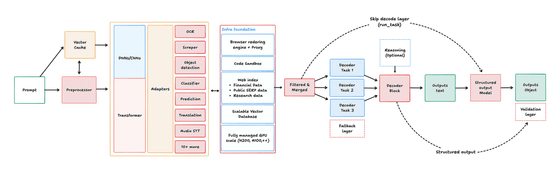
핵심 포인트: ‘만능 AI’가 아닌 ‘정형 작업 특화 AI’
중요한 점은 Interfaze가 ‘LLM을 대체하는 만능 AI’가 아니라, OCR, 음성 인식, 구조화 출력 등 개발자가 대량으로 처리하는 정형 작업에 특화된 AI로 설계되었다는 것입니다. 기사에서도 Claude Opus나 GPT-5.5 같은 고성능 범용 모델은 코딩이나 복잡한 추론에서 강력하지만, OCR이나 번역 같은 대량 처리에서는 비용과 속도 면에서 사용하기 어렵다고 설명합니다.
Interfaze의 주요 사양은 다음과 같습니다.
컨텍스트 윈도우: 100만 토큰
최대 출력: 3만 2000 토큰
입력 형식: 텍스트, 이미지, 음성, 파일
추론 기능: 기본적으로 비활성화
가격: Gemini-3-Flash와 유사한 수준 (입력 100만 토큰당 1.50달러, 출력 100만 토큰당 3.50달러)
OCR 성능: 복잡한 레이아웃의 PDF도 정확하게
Interfaze가 특히 중점을 둔 분야는 OCR입니다. 긴 PDF, 복잡한 레이아웃의 문서, 이미지 내 문자 인식 등에서 문자뿐만 아니라 도표나 그래픽의 위치도 동시에 처리할 수 있는 점이 강점입니다. 예를 들어, 잡지처럼 여러 단으로 구성된 페이지를 입력하면 페이지 내 텍스트를 추출하면서 일러스트나 도판의 좌표도 JSON 형식으로 반환할 수 있습니다.
아래 그래프는 길고 레이아웃이 복잡한 PDF에 대한 OCR 정확도를 비교한 결과입니다. Interfaze가 85.7%로 가장 높은 성능을 보이며, Chandra OCR, olmOCR, Grok-4.3, GPT-5.4-Mini 등을 앞질렀습니다.
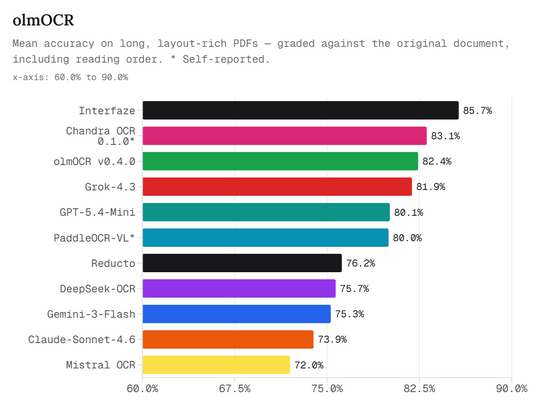
Interfaze가 OCR에서 강력한 이유는 단순히 CNN 인코더가 글자를 잘 읽는 것뿐만 아니라, 도판이나 그래픽 검출, 번역 레이어, Transformer를 통한 의미 이해를 동일한 벡터 공간에서 결합할 수 있기 때문입니다.
구조화 출력: JSON 값의 정확성까지 검증
또 다른 중요한 분야는 구조화 출력입니다. 많은 LLM은 JSON 스키마에 따른 형식으로 출력하는 데 능숙하지만, 그 안에 들어가는 값이 항상 정확한 것은 아닙니다. 예를 들어 ‘이름’, ‘주소’, ‘날짜’, ‘금액’ 같은 항목을 깔끔한 JSON으로 반환하더라도 값 자체가 틀리면 실무에서 사용할 수 없습니다.
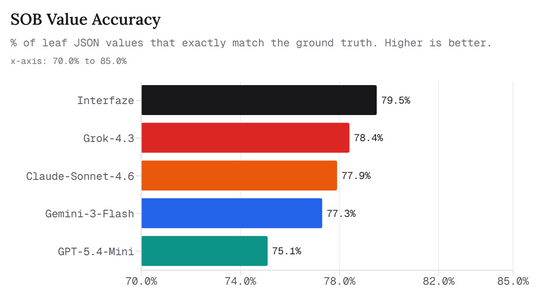
Interfaze는 이 문제를 측정하기 위해 Structured Output Benchmark(SOB) 를 공개했습니다. SOB는 모델에 정답 정보를 컨텍스트로 제공하고, 해당 정보를 JSON으로 올바르게 출력할 수 있는지를 측정합니다. 평가 대상은 텍스트, 이미지, 음성을 포함하며, JSON의 최종 값이 정답과 완전히 일치하는지 여부로 정확도를 측정합니다.
아래 그래프는 JSON 최종 값이 정답과 완전히 일치한 비율(SOB Value Accuracy)을 보여줍니다. Interfaze는 79.5%로 1위를 기록하며, Grok-4.3, Claude-Sonnet-4.6, Gemini-3-Flash, GPT-5.4-Mini를 소폭 앞질렀습니다.
다국어 및 음성 인식 성능
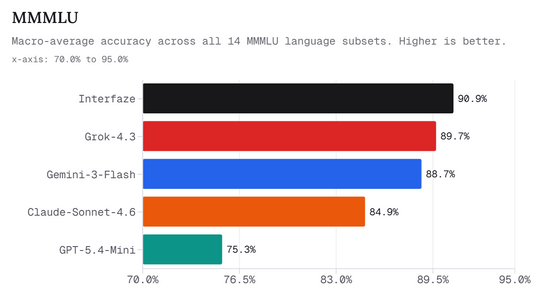
다국어 성능에서도 Interfaze는 높은 점수를 보여줍니다. MMMLU는 여러 언어에 대한 지식과 이해력을 측정하는 벤치마크로, 영어 이외의 언어 처리를 얼마나 안정적으로 처리하는지 평가합니다.
아래 그래프는 14개 언어 MMMLU 하위 집합의 매크로 평균 정확도를 보여줍니다. Interfaze는 90.9% 로, Grok-4.3(89.7%), Gemini-3-Flash(88.7%)를 상회했습니다.
음성 인식(자동 음성 인식, ASR)에서도 Interfaze는 전문 음성 인식 서비스에 근접한 성능을 보여줍니다. VoxPopuli-Cleaned-AA는 유럽 의회의 다국어 연설을 대상으로 한 음성 인식 벤치마크로, 단어 오류율(WER)로 평가합니다.
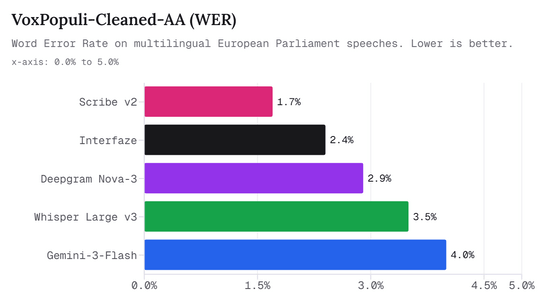
아래 그래프는 VoxPopuli-Cleaned-AA에서의 WER을 비교한 결과입니다. 가장 낮은 오류율은 Scribe v2의 1.7%이고, Interfaze는 2.4%로 2위를 기록했지만, Deepgram Nova-3, Whisper Large v3, Gemini-3-Flash보다 낮은 오류율을 보였습니다.
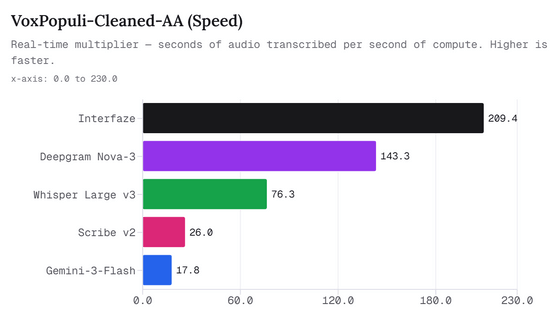
또한 Interfaze는 음성 인식 속도에서도 강점을 보입니다. 기사에 따르면, Interfaze는 1초의 계산 시간으로 209초 분량의 음성을 처리할 수 있습니다. 이는 Deepgram Nova-3의 약 1.5배, Scribe v2의 약 8배, Gemini-3-Flash의 11배 이상에 해당합니다.
아래 그래프는 VoxPopuli-Cleaned-AA에서의 전사 속도를 비교한 결과입니다. Interfaze가 209.4로 1위를 기록하며, Deepgram Nova-3(143.3), Whisper Large v3(76.3)를 크게 앞질렀습니다.
종합 벤치마크 및 API 제공
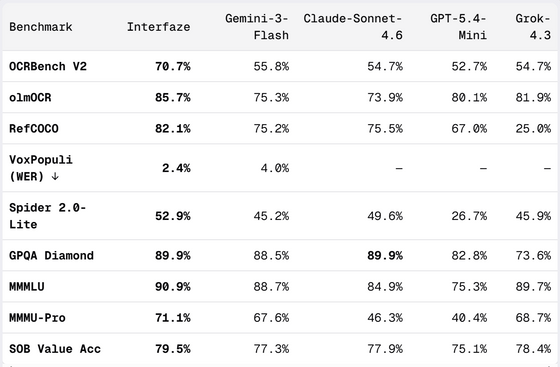
기사 전체의 벤치마크에서는 OCRBench V2, olmOCR, RefCOCO, VoxPopuli, Spider 2.0-Lite, GPQA Diamond, MMMLU, MMMU-Pro, SOB Value Accuracy 등 9개 항목이 비교되었습니다. Interfaze는 많은 항목에서 최상위 또는 상위권에 올랐으며, 특히 OCR, 구조화 출력, 다국어 처리, 음성 인식 속도에서 눈에 띄는 결과를 보여주었습니다.
Interfaze는 OpenAI 호환 Chat Completions API로 제공되며, 기존 OpenAI SDK, Vercel AI SDK 등을 통해 쉽게 사용할 수 있습니다.













